

Mit der raschen Entwicklung und breiten Anwendung von Technologien zur Sprachmodellierung in großem Maßstab rücken deren potenzielle Sicherheitsrisiken zunehmend in den Mittelpunkt des Interesses der Branche. Um diesen Herausforderungen zu begegnen, haben viele führende Technologieunternehmen, Standardisierungsorganisationen und Forschungsinstitute in der ganzen Welt ihre eigenen Sicherheitsrahmenwerke entwickelt und veröffentlicht. In diesem Papier werden wir neun repräsentative Sicherheitsrahmen für große Modelle heraussuchen und analysieren, mit dem Ziel, eine klare Referenz für Praktiker in verwandten Bereichen zu bieten.

Abbildung: Überblick über das Big Model Security Framework
Googles Secure AI Framework (SAIF) (veröffentlicht 2025.04)
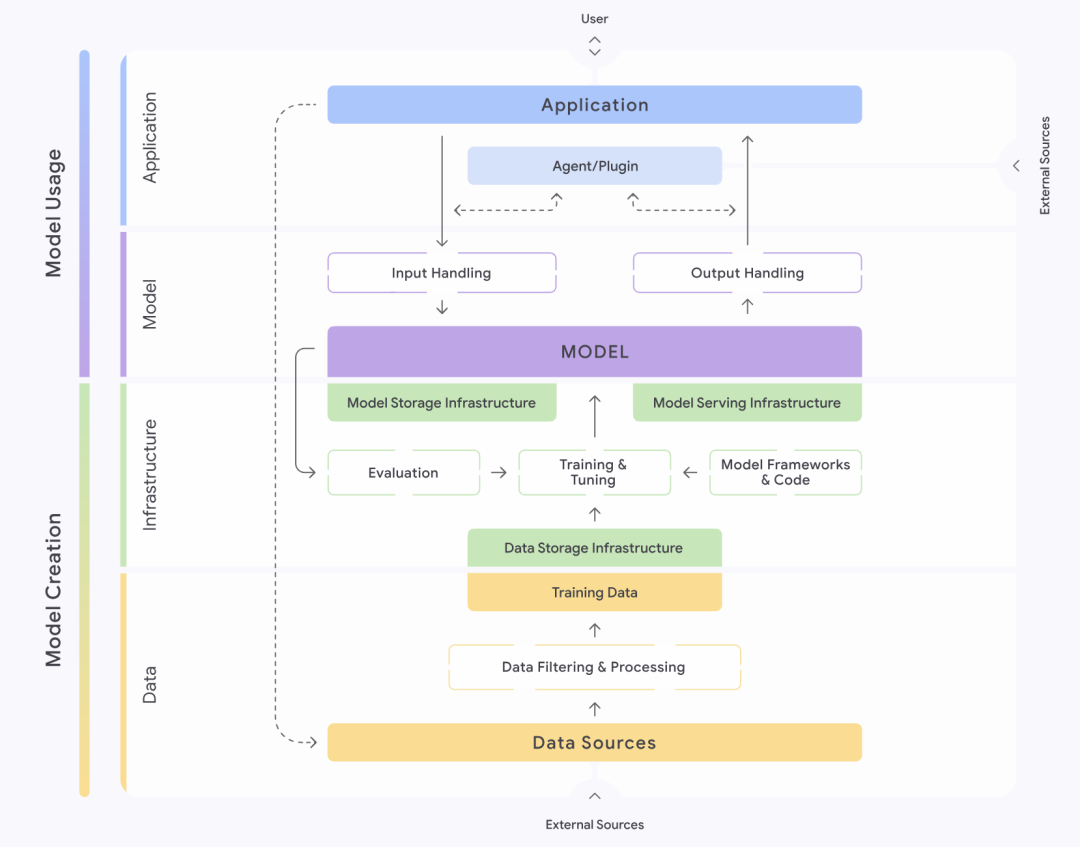
Abbildung: Google SAIF-Rahmenstruktur
Das von Google (Google) eingeführte Secure AI Framework, kurz SAIF, bietet einen strukturierten Ansatz für das Verständnis und die Verwaltung der Sicherheit von KI-Systemen. Das Rahmenwerk unterteilt KI-Systeme akribisch in vier Schichten: Daten, Infrastruktur, Modell und Anwendung. Jede Ebene wird weiter in verschiedene Komponenten unterteilt, wie z. B. die Datenebene, die wichtige Teile wie Datenquellen, Datenfilterung und -verarbeitung sowie Trainingsdaten usw. enthält. Das SAIF betont, dass jeder dieser Teile spezifische Risiken und Gefahren birgt.
Auf der Grundlage des gesamten Lebenszyklus eines KI-Systems identifiziert und sortiert SAIF fünfzehn Hauptrisiken, darunter Data Poisoning, unbefugter Zugriff auf Trainingsdaten, Manipulation der Modellquelle, exzessive Datenverarbeitung, Modelllecks, Manipulation der Modellbereitstellung, Modell-Denial-of-Service, Modell-Reverse-Engineering, unsichere Komponenten, Cue-Word-Injektionen, Modellverschlüsselung, Leckagen sensibler Daten, Zugriff auf sensible Daten durch Extrapolationen, unsichere Modellausgabe und böswilliges Verhalten. Als Reaktion auf diese fünfzehn Risiken schlägt das SAIF auch fünfzehn Präventiv- und Kontrollmaßnahmen vor, die den Kern seiner Sicherheitsleitlinien bilden.
OWASP's Top 10 Sicherheitsbedrohungen für Big Model Anwendungen (Veröffentlicht 2025.03)

Abbildung: Die 10 größten Sicherheitsbedrohungen für OWASP Big Model-Anwendungen
Das Open World Application Security Project (OWASP), eine führende Kraft im Bereich der Cybersicherheit, hat ebenfalls seine Top-10-Liste der Sicherheitsbedrohungen für Big-Model-Anwendungen veröffentlicht. OWASP unterteilt Big-Model-Anwendungen in mehrere wichtige "Vertrauensbereiche", darunter den Big-Model-Dienst selbst, Funktionen von Drittanbietern Plug-Ins, private Datenbanken und externe Trainingsdaten. Die Organisation identifiziert eine Reihe von Sicherheitsbedrohungen, sowohl in den Interaktionen zwischen diesen Vertrauensbereichen als auch innerhalb der Vertrauensbereiche.
Die 10 wichtigsten Sicherheitsbedrohungen der OWASP sind in der Reihenfolge ihrer Auswirkungen: Prompt Injection, Offenlegung sensibler Informationen, Risiken in der Lieferkette, Daten- und Modellvergiftung, unsachgemäße Verarbeitung von Ausgaben, Überautorisierung, System Prompt Leakage, Schwachstellen in Vektoren und Einbettung, irreführende Informationen und unbegrenzter Ressourcenverbrauch. Für jede dieser Bedrohungen bietet OWASP Empfehlungen zur Vorbeugung und Kontrolle, die Entwicklern und Sicherheitspersonal eine praktische Anleitung bieten.
OpenAI's Model Safety Framework (laufend aktualisiert)
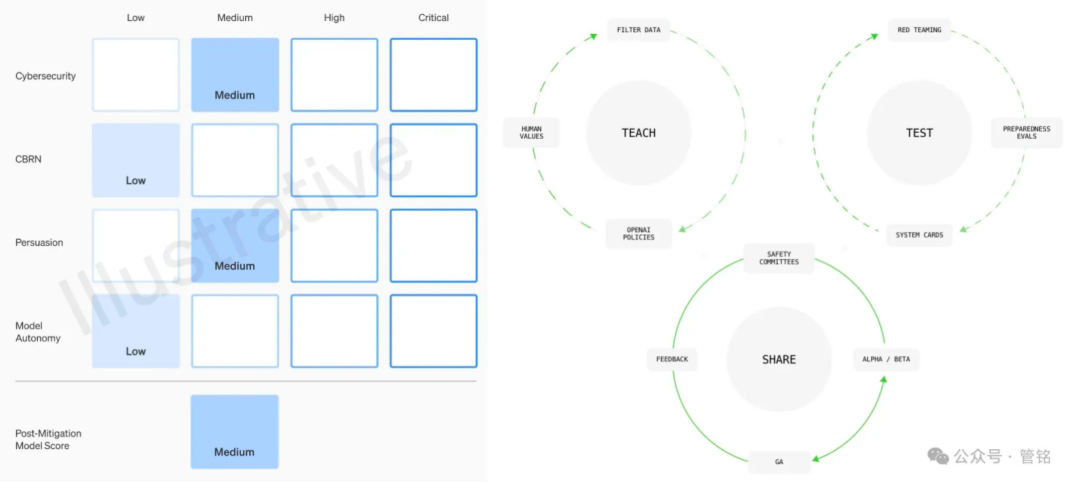
Abbildung: Dimensionen des Sicherheitsrahmens des OpenAI-Modells
Als führendes Unternehmen im Bereich der Big-Model-Technologie räumt OpenAI der Sicherheit seiner Modelle hohe Priorität ein. Der Modellsicherheitsrahmen basiert auf vier Dimensionen: CBRN-Risiko (Massenvernichtungswaffen), Cyberangriffsfähigkeit, Überzeugungskraft (die Fähigkeit von Modellen, menschliche Meinungen und Verhaltensweisen zu beeinflussen) und Modellautonomie, die je nach dem Grad des potenziellen Schadens als niedrig, mittel, hoch oder schwerwiegend eingestuft werden. Vor jeder Modellfreigabe muss auf der Grundlage dieses Rahmens eine detaillierte Sicherheitsbewertung, die so genannte Systemkarte, vorgelegt werden.
Darüber hinaus schlägt OpenAI einen Governance-Rahmen vor, der Werteabgleich, kontradiktorische Bewertung und Kontrolliteration umfasst. In der Phase der Werteanpassung verpflichtet sich OpenAI, eine Reihe von Modellverhaltensweisen zu formulieren, die mit universellen menschlichen Werten übereinstimmen, und die Datenbereinigung in allen Phasen des Modelltrainings zu steuern. In der kontradiktorischen Evaluierungsphase wird OpenAI professionelle Testfälle erstellen, um das Modell vor und nach der Durchführung von Schutzmaßnahmen umfassend zu testen, und schließlich Systemkarten erstellen. In der Phase der Kontrolliteration wird OpenAI eine Batch-Launch-Strategie für bereits eingesetzte Modelle anwenden und weiterhin Schutzmaßnahmen hinzufügen und optimieren.
AI Security Governance Framework for Cybersecurity Standards Committee (veröffentlicht 2024.09)
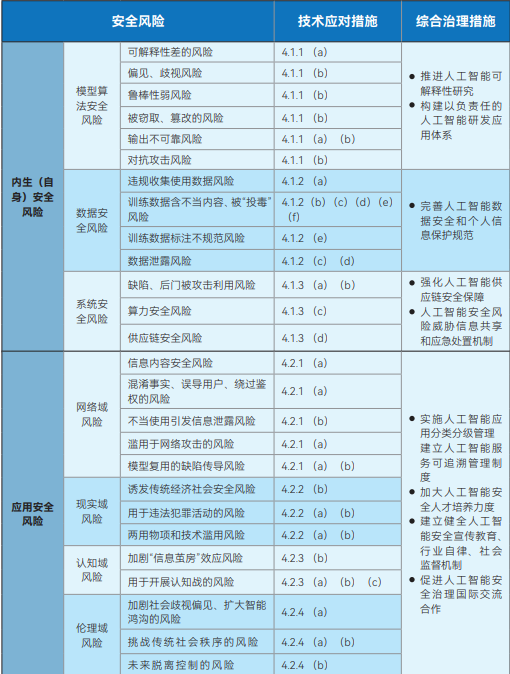
Abbildung: Ausschuss für den Standard für Netzsicherheit AI Security Governance Framework
Das vom National Cyber Security Standardisation Technical Committee (NCSSTC) veröffentlichte Artificial Intelligence Safety Governance Framework zielt darauf ab, eine Makroanleitung für die sichere Entwicklung von KI zu geben. Der Rahmen unterteilt die KI-Sicherheitsrisiken in zwei Hauptkategorien: endogene (eigene) Sicherheitsrisiken und Anwendungssicherheitsrisiken. Endogene Sicherheitsrisiken beziehen sich auf die dem Modell selbst innewohnenden Risiken, zu denen hauptsächlich Sicherheitsrisiken des Modellalgorithmus, der Daten und des Systems gehören. Das Anwendungssicherheitsrisiko hingegen bezieht sich auf die Risiken, denen das Modell bei der Anwendung ausgesetzt sein kann, und wird weiter in vier Aspekte unterteilt: Netzwerkbereich, Realitätsbereich, kognitiver Bereich und ethischer Bereich.
Als Reaktion auf diese identifizierten Risiken weist der Rahmen klar darauf hin, dass die Entwickler von Modellen und Algorithmen, Dienstanbieter, Systemnutzer und andere relevante Parteien aktiv technische Maßnahmen ergreifen müssen, um sie unter einer Vielzahl von Aspekten zu verhindern, wie z. B. Trainingsdaten, arithmetische Einrichtungen, Modelle und Algorithmen, Produkte und Dienstleistungen sowie Anwendungsszenarien. Gleichzeitig befürwortet der Rahmen die Einrichtung und Verbesserung eines umfassenden Governance-Systems für KI-Sicherheitsrisiken, das technologische Forschungs- und Entwicklungseinrichtungen, Dienstanbieter, Nutzer, Regierungsstellen, Industrieverbände und gesellschaftliche Organisationen einbezieht.
Sicherheitsstandardsystem für künstliche Intelligenz des Ausschusses für Cybersicherheit V1.0 (veröffentlicht 2025.01)
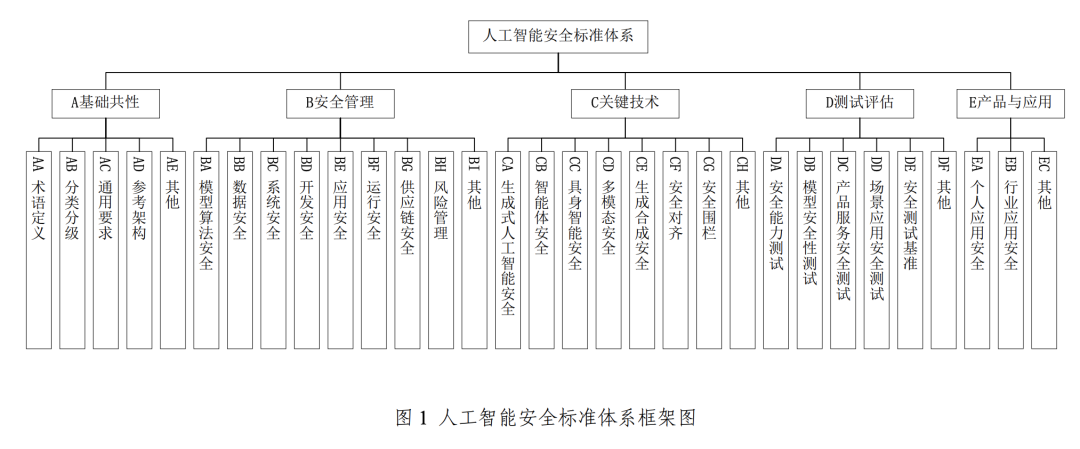
Abbildung: Ausschuss für den Netzsicherheitsstandard "Artificial Intelligence Security Standard System V1.0
Zur Unterstützung und Umsetzung des oben erwähnten Artificial Intelligence Security Governance Framework hat das CNSC außerdem das Artificial Intelligence Security Standard System V1.0 eingeführt, das systematisch Schlüsselstandards zusammenstellt, die helfen können, relevante KI-Sicherheitsrisiken zu verhindern und zu lösen, und sich auf eine effektive Schnittstelle mit dem bestehenden nationalen Standardsystem für Cybersicherheit konzentriert.
Dieses Normsystem besteht im Wesentlichen aus fünf Kernbereichen: grundlegende Gemeinsamkeiten, Sicherheitsmanagement, Schlüsseltechnologie, Prüfung und Bewertung sowie Produkte und Anwendungen. Der Teil "Sicherheitsmanagement" umfasst die Bereiche Modellalgorithmus-Sicherheit, Datensicherheit, Systemsicherheit, Entwicklungssicherheit, Anwendungssicherheit, Betriebssicherheit und Sicherheit der Lieferkette. Der Abschnitt über die Schlüsseltechnologie konzentriert sich dagegen auf innovative Bereiche wie generative KI-Sicherheit, Sicherheit des intelligenten Körpers, Sicherheit der verkörperten Intelligenz (in Bezug auf KI mit physischen Entitäten wie Robotern, deren Sicherheit Interaktionen mit der physischen Welt beinhaltet), multimodale Sicherheit, generative Synthese-Sicherheit, Sicherheitsabgleich und Sicherheitszäune.
Big Model Security Practices 2024 von Tsinghua University, Zhongguancun Lab und Ant Group (veröffentlicht 2024.11)
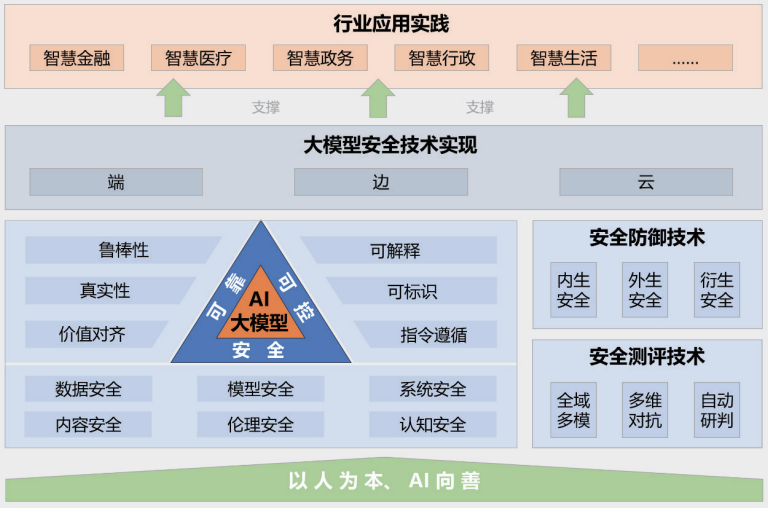
Abbildung: Big Model Sicherheitspraktiken 2024 Rahmen
Der Bericht "Big Model Security Practice 2024", der gemeinsam von der Tsinghua-Universität, dem Zhongguancun Lab und der Ant Group veröffentlicht wurde, bietet Einblicke in die Big Model Security aus der Perspektive der Integration von Industrie, Wissenschaft und Forschung. Der in dem Bericht vorgeschlagene Rahmen für Big Model Security umfasst fünf Hauptteile: das Leitprinzip "Menschenorientiert, KI für das Gute"; ein sicheres, zuverlässiges und kontrollierbares Big Model Security-Technologie-System; Sicherheitsmess- und Verteidigungstechnologien; End-to-End-, Edge-to-Edge- und Cloud-Collaborative-Security-Technologie-Implementierungen; und Anwendungsfälle in verschiedenen Branchen.
Der Bericht weist detailliert auf die zahlreichen Risiken und Herausforderungen hin, mit denen große Modelle derzeit konfrontiert sind, z. B. Datenlecks, Datendiebstahl, Datenvergiftung, gegnerische Angriffe, Befehlsangriffe (Herbeiführung unbeabsichtigter Verhaltensweisen in Modellen durch gut konzipierte Befehle), Modelldiebstahlsangriffe, Hardware-Sicherheitsschwachstellen, Softwaresicherheitsschwachstellen, Sicherheitsprobleme im Rahmen selbst, Sicherheitsrisiken durch externe Tools, Erzeugung toxischer Inhalte, Verbreitung parteiischer Inhalte, Erzeugung gefälschter Informationen, ideologische Risiken, Telekommunikationsbetrug und Identitätsdiebstahl, Integritätskrise in der Bildungsbranche und durch Vorurteile bedingte Fairnessprobleme. Generierung von Fehlinformationen, ideologische Risiken, Telekommunikationsbetrug und Identitätsdiebstahl, Verletzung von geistigem Eigentum und Urheberrechten, Integritätskrise in der Bildungsindustrie und durch Vorurteile verursachte Fairnessprobleme. Der Bericht schlägt auch entsprechende Abwehrtechniken vor, um diesen komplexen Risiken zu begegnen.
Big Model Security Forschungsbericht von Aliyun und ICTA (veröffentlicht 2024.09)
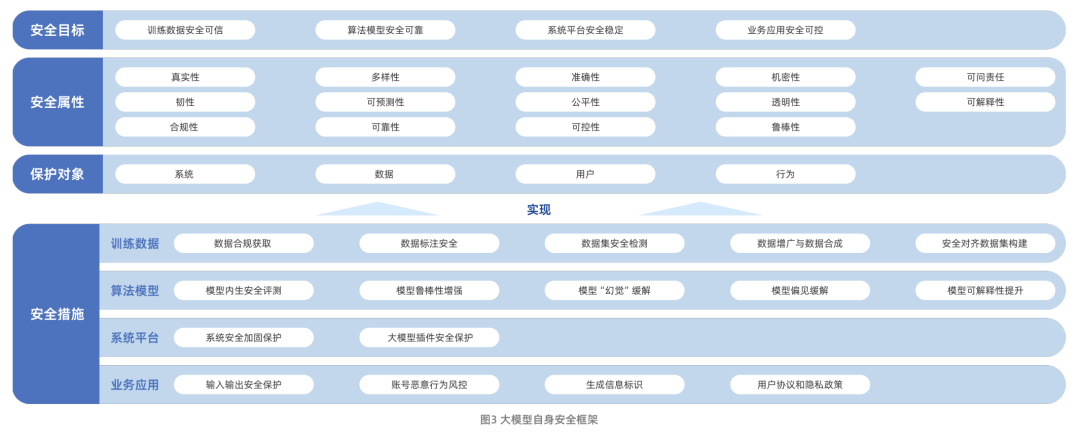
Abbildung: Aliyun & ICTA Big Model Security Research Report Framework
Der Big Model Security Research Report, der gemeinsam von Aliyun und der China Academy of Information and Communications Technology (CAICT) veröffentlicht wurde, beschreibt systematisch den Entwicklungspfad der Big Model-Technologie und die Sicherheitsherausforderungen, mit denen sie derzeit konfrontiert ist. Zu diesen Herausforderungen gehören vor allem die Risiken für die Datensicherheit, die Sicherheit der algorithmischen Modelle, die Sicherheit der Systemplattform und die Sicherheit der Geschäftsanwendungen. Es ist erwähnenswert, dass der Bericht den Forschungsbereich der Big-Model-Sicherheit von der Sicherheit des Modells selbst auf die Frage ausweitet, wie Big-Model-Technologie genutzt werden kann, um die traditionellen Fähigkeiten zum Schutz der Netzwerksicherheit zu stärken und zu verbessern.
Was die Sicherheit des Modells selbst betrifft, so wird in dem Bericht ein Rahmen mit vier Dimensionen geschaffen: Sicherheitsziele, Sicherheitsattribute, Schutzobjekte und Sicherheitsmaßnahmen. Dabei konzentrieren sich die Sicherheitsmaßnahmen auf die vier Kernaspekte Trainingsdaten, Modellalgorithmen, Systemplattformen und Geschäftsanwendungen und spiegeln damit einen Rundumschutzgedanken wider.
Tencent Research Institute's Big Model Security and Ethics Study 2024 (veröffentlicht 2024.01)

Abbildung: Tencent Research Institute's Big Model Sicherheits- und Ethik-Forschungsbelange
Der Bericht "Big Model Security and Ethics Research 2024", der vom Tencent Research Institute veröffentlicht wurde, bietet eine eingehende Analyse der Trends in der Big-Model-Technologie sowie der Chancen und Herausforderungen, die diese Trends für die Sicherheitsbranche darstellen. Der Bericht listet fünfzehn Hauptrisiken auf, darunter Datenlecks, Datenvergiftung, Modellmanipulationen, Vergiftung der Lieferkette, Hardware-Schwachstellen, Komponenten-Schwachstellen und Plattform-Schwachstellen. Gleichzeitig werden in dem Bericht vier Best Practices für die Sicherheit von Big Models vorgestellt: Prompt Security Assessment, Big Model Blue Army Attack and Defense Exercise, Big Model Source Code Security Protection Practice und Big Model Infrastructure Vulnerability Security Protection Scheme.
Der Bericht beleuchtet auch Fortschritte und künftige Trends bei der Anpassung der Werte von Big Models. Der Bericht stellt fest, dass die Frage, wie sichergestellt werden kann, dass die Fähigkeiten und Verhaltensweisen von Big Models mit menschlichen Werten, wahren Absichten und ethischen Grundsätzen in Einklang gebracht werden, um Sicherheit und Vertrauen in den Prozess der Zusammenarbeit zwischen Menschen und KI zu gewährleisten, zu einem Kernthema der Big Model Governance geworden ist.
360's Big Model Sicherheitslösung (laufend aktualisiert)
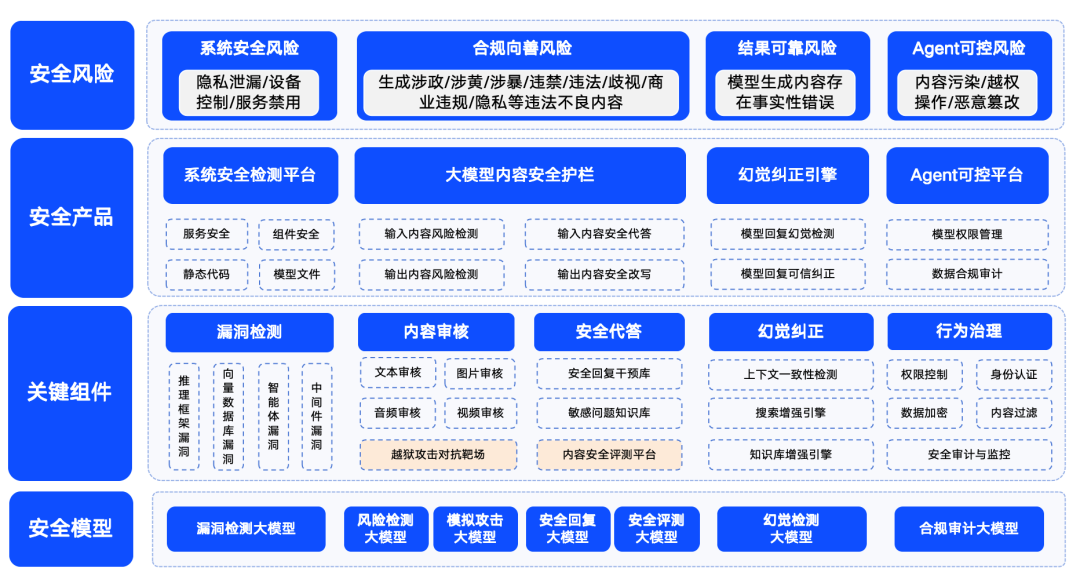
Abbildung: Schema der 360 Big Model-Sicherheitslösung
Qihoo 360 hat sich ebenfalls aktiv mit der Sicherheit von Großmodellen befasst und seine Sicherheitslösungen vorgestellt.360 fasst die Sicherheitsrisiken von Großmodellen in vier Kategorien zusammen: Systemsicherheitsrisiken, Inhaltssicherheitsrisiken, vertrauenswürdige Sicherheitsrisiken und kontrollierbare Sicherheitsrisiken. Dabei bezieht sich die Systemsicherheit hauptsächlich auf die Sicherheit der verschiedenen Arten von Software im Ökosystem großer Modelle; die Inhaltssicherheit konzentriert sich auf das Konformitätsrisiko von Eingabe- und Ausgabeinhalten; die vertrauenswürdige Sicherheit konzentriert sich auf die Lösung des "Illusions"-Problems des Modells (d. h. das Modell erzeugt Informationen, die vernünftig erscheinen, aber nicht real sind); und die kontrollierbare Sicherheit befasst sich mit dem komplexeren Problem der Sicherheit von Agentenprozessen. Kontrollierte Sicherheit befasst sich mit dem komplexeren Problem der Sicherheit von Agentenprozessen.
Um sicherzustellen, dass Großmodelle sicher, gut, vertrauenswürdig und kontrollierbar für die Anwendung in verschiedenen Branchen sind, hat 360 eine Reihe von Sicherheitsprodukten für Großmodelle entwickelt, die auf den eigenen Fähigkeiten im Bereich der Großmodelle basieren. Zu diesen Produkten gehören "360 Smart Forensics", das hauptsächlich auf die Aufdeckung von Schwachstellen im LLM-Ökosystem abzielt, "360 Smart Shield", das sich auf die inhaltliche Sicherheit von Großmodellen konzentriert, und "360 Smart Search", das glaubwürdige Sicherheit garantiert. 360SmartSearch". Durch die Kombination dieser Produkte hat 360 eine Reihe von relativ ausgereiften Sicherheitslösungen für große Modelle in einem frühen Stadium geschaffen.













