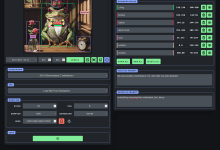
Allgemeine Einführung ChatTTS ist ein generatives Sprachmodell, das für Dialogszenarien entwickelt wurde. Es erzeugt natürliche und ausdrucksstarke Sprache, unterstützt mehrere Sprachen und mehrere Sprecher und ist für interaktive Dialoge geeignet. Das Modell geht über das Grobe hinaus, indem es feinkörnige prosodische Merkmale wie Lachen, Pausen und Zwischenrufe vorhersagt und kontrolliert...
Umfassende Einführung MoneyPrinterPlus ist ein Open-Source-Projekt, das darauf abzielt, alle Arten von Kurzvideos mit einem Klick durch KI-Technologie zu erzeugen und zu mischen und sie automatisch auf mehreren Videoplattformen wie Jieyin, Shutterbugs, Xiaohongshu und Video Number zu veröffentlichen. Das Tool unterstützt lokale und cloudbasierte Sprachmodelle, darunter chatTTS, fasterwhisper, G...
Aktivieren Sie Builder intelligenten Programmiermodus, unbegrenzte Nutzung von DeepSeek-R1 und DeepSeek-V3, reibungslosere Erfahrung als die Übersee-Version. Geben Sie einfach die chinesischen Befehle, keine Programmierkenntnisse können auch Null-Schwelle, um ihre eigenen Anwendungen zu schreiben.
Umfassende Einführung TF-ID (Table/Figure IDentifier) ist eine Familie von Objekterkennungsmodellen zur Extraktion von Tabellen und Bildern aus wissenschaftlichen Arbeiten. Das Projekt wurde von Yifei Hu entwickelt und auf GitHub veröffentlicht. TF-ID-Modelle sind darauf abgestimmt, Tabellen und Bilder aus wissenschaftlichen Arbeiten zu erkennen und zu extrahieren...
Allgemeine Einführung Chatbot UI ist ein Open-Source-Projekt, das Entwicklern helfen soll, personalisierte und intelligente Konversationsschnittstellen zu erstellen. Das Projekt bietet eine Reihe von Schnittstellenkomponenten und interaktiven Funktionen, die einfach in ein bestehendes Chatbot-System integriert werden können, um den Nutzern ein reibungsloseres und intelligenteres Dialogerlebnis zu bieten...
Allgemeine Einführung GLIGEN GUI ist eine intuitive grafische Benutzeroberfläche auf der Basis von ComfyUI, die die Verwendung des GLIGEN-Modells vereinfacht, eines neuartigen Text-Bild-Modells, das die präzise Angabe der Position von Objekten in einem Bild ermöglicht. Mit GLIGEN GUI wird der Benutzer aufgefordert, Kästchen zu zeichnen und Text einzugeben...
Umfassende Einführung Easy-Voice-Toolkit ist ein multifunktionales Toolkit, das auf dem Open Source Speech Project basiert und eine breite Palette an automatisierten Audiowerkzeugen für die Spracherkennung, Sprachtranskription, Sprachkonvertierung, Datensatzerstellung und Modelltraining bietet. Benutzer können diese Werkzeuge je nach Bedarf selektiv oder sequentiell einsetzen...
Allgemeine Einführung FaceFusion ist eine fortschrittliche Cloud-Plattform mit integrierten Gesichtsaustausch- und -verbesserungsfunktionen, die den Bild-zu-Video- und Bild-zu-Bild-Austauschprozess mit 5 professionellen Modellen optimiert, um eine makellose Ausgabe zu gewährleisten. Darüber hinaus führt es eine Gesichtsverbesserung mit 7 Modellen durch, wobei 3 verschiedene Modelle zur...
Allgemeine Einführung Kotaemon ist ein quelloffenes Q&A-Tool für Dokumente, das Endnutzern und Entwicklern Q&A-Funktionen auf der Grundlage von Retrieval Augmented Generation (RAG) bietet. Das von Cinnamon entwickelte Projekt unterstützt eine Vielzahl von LLM-API-Anbietern (z.B. OpenAI, AzureOpenAI, Cohere, etc.) sowie native...
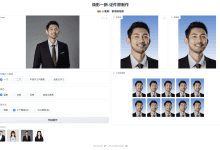
Umfassende Einführung HivisionIDPhotos ist ein Open-Source-Leichtbau-KI-Dokument Foto-Produktions-Tools, kann intelligent identifizieren den Benutzer Foto-Szene und Keying, um ein Standard-Dokument Foto im Einklang mit einer Vielzahl von Spezifikationen zu generieren. Das Tool unterstützt benutzerdefinierte Hintergrundfarbe und Größe, die Zukunft wird auch Schönheit und intelligente Änderung der formalen Kleidungsfunktion einzuführen. Mit...
Allgemeine Einführung Marker ist ein auf Deep Learning basierendes Tool zur Dokumentenverarbeitung, das PDF-Dateien schnell und präzise in das Markdown-Format konvertiert. Es unterstützt eine breite Palette von Dokumenttypen und ist besonders für die Konvertierung von Büchern und wissenschaftlichen Arbeiten optimiert.Marker ist in der Lage, überflüssige Inhalte wie Kopf- und Fußzeilen zu entfernen, Tabellen zu formatieren und...
Allgemeine Einführung SadTalker ist ein Open-Source-Tool, das einzelne Porträtfotos und Audiodateien kombiniert, um realistische Videos mit sprechenden Köpfen für eine Vielzahl von Szenarien zu erstellen, z. B. für personalisierte Nachrichten, Bildungsinhalte und mehr. Der revolutionäre Einsatz von 3D-Modellierungstechnologien wie ExpNet und PoseVAE zeichnet sich durch die Erfassung der subtilen Facetten...
Allgemeine Einführung VideoReTalking ist ein innovatives System, das es dem Benutzer ermöglicht, lippensynchrone Gesichtsvideos auf der Grundlage des Eingangsaudios zu generieren, wobei qualitativ hochwertige und lippensynchrone Ausgangsvideos auch mit unterschiedlichen Emotionen erzeugt werden. Das System unterteilt dieses Ziel in drei aufeinander folgende Aufgaben: Erzeugung von Gesichtsvideos mit typischen Ausdrücken...
Allgemeine Einführung MuseV ist ein öffentliches Projekt auf GitHub, das die Erzeugung von Avatar-Videos von unbegrenzter Länge und hoher Wiedergabetreue ermöglichen soll. Es basiert auf Diffusionstechnologie und bietet Image2Video, Text2Image2Video, Video2Video und viele andere Funktionen. Bietet Modellstruktur, Anwendungsfälle, Schnellstart...
Umfassende Einführung Unstructured-IO bietet eine Reihe von Open-Source-Komponenten für die Verarbeitung und Vorverarbeitung von Bildern und Textdokumenten wie PDF, HTML, Word-Dokumente, usw. Unstructured-IO bietet eine Reihe von Open-Source-Komponenten für die Verarbeitung und Vorverarbeitung von Bildern und Textdokumenten wie PDF, HTML, Word-Dokumente, usw. Sein Hauptziel ist es, Datenverarbeitungs-Workflows zu vereinfachen und zu optimieren, insbesondere für große Sprachmodell (LLM)-Anwendungen zu unterstützen.Unstructured...
Allgemeine Einführung magic-html ist eine Python-Bibliothek, die den Prozess der Extraktion von Body-Region-Inhalten aus HTML vereinfachen soll. Egal, ob es sich um komplexe HTML-Strukturen oder einfache Webseiten handelt, diese Bibliothek zielt darauf ab, dem Benutzer eine bequeme und effiziente Schnittstelle zu bieten. Sie unterstützt multimodale Extraktion, Extraktion mehrerer Layouts...
WebPilot Allgemeine Einführung Webpilot ist ein freier und quelloffener "Web-Assistent", der es Ihnen ermöglicht, frei mit jeder Webseite zu kommunizieren oder automatisierte Aufgaben auszuführen. Anstatt Seiten zu wechseln oder zu kopieren und einzufügen, wählen Sie einfach Text aus oder geben Befehle ein, und Webpilot versorgt Sie mit Echtzeit-Informationen und intelligenten...
Umfassende Einführung DB-GPT ist ein Open-Source-Framework zur Entwicklung nativer KI-Datenanwendungen, das auf AWEL (Agentic Workflow Expression Language) und Smart-Body-Technologien basiert. Das Projekt zielt darauf ab, eine Infrastruktur im Bereich großer Modelle aufzubauen, indem mehrere technische Fähigkeiten entwickelt werden, darunter ein Multi-Modell-Management-System (SMMF),...
DreamTalk Umfassende Einführung DreamTalk ist ein von der Tsinghua Universität, der Alibaba Gruppe und der Huazhong Universität für Wissenschaft und Technologie gemeinsam entwickeltes, diffusionsmodellgesteuertes Framework zur Erzeugung von Sprechern. Es besteht hauptsächlich aus drei Teilen: einem Netzwerk zur Rauschunterdrückung, einem Lippenexperten und einem Stilprädiktor und kann eine Vielzahl von Audioeingaben auf der Grundlage von...
Umfassende Einführung InstantID ist eine fortschrittliche Technologie, die darauf ausgerichtet ist, Bilder mit personalisierten Stilen oder Posen in Sekundenschnelle zu generieren und dabei ein hohes Maß an Wiedergabetreue anhand eines einzigen Referenz-ID-Bildes zu gewährleisten. Die Technologie verwendet eine auf einem Diffusionsmodell basierende Lösung, die Gesichtsbilder, Landmarkenbilder und...
Sie können keine AI-Tools finden? Versuchen Sie es hier!
Geben Sie einfach das Schlüsselwort Barrierefreiheit Bing-SucheDer Bereich KI-Tools auf dieser Website bietet eine schnelle und einfache Möglichkeit, alle KI-Tools auf dieser Website zu finden.