Following the launch of the next generation of open models last month Gemma 3 Google recently expanded its model ecosystem with a new version optimized for Quantization-Aware Training (QAT). Gemma 3 has previously been recognized for its BF16 Accuracy is better than a single high-end GPU (e.g. NVIDIA H100), proving its leading performance with the ability to run on a wide range of consumer-grade hardware. And the QAT version is designed to significantly reduce the memory requirements of the model while maintaining the highest quality output possible, enabling powerful AI models to run on more consumer-grade hardware.

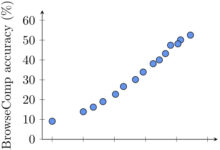
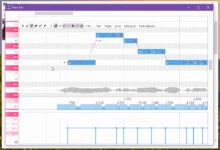
This chart ranks AI models based on Chatbot Arena Elo scores, with higher scores representing higher user preference. The dots indicate what the model needs to run NVIDIA H100 The estimated number of GPUs.
Understanding Performance, Accuracy and Quantization Thresholds
The graph above shows a comparison of the performance (Elo scores) of recently released large language models. Higher bars imply that the model performs better in anonymous side-by-side comparisons performed by human evaluators. The bottom of the chart is labeled with the performance of the model in BF16 required to run each model under the data type NVIDIA H100 GPU Estimated Number.
option BF16 The comparison is made because it is a common numerical format used for many large model inference, representing model parameters stored in 16-bit precision. In the case of the unified BF16 Comparisons under the setup help to evaluate the inherent capabilities of the model itself in the same inference configuration, excluding variables introduced by different hardware or optimization techniques such as quantization.
It is worth noting that while the chart uses BF16 make a fair comparison, but in the actual deployment of very large models, in order to reduce the huge demand on hardware (e.g., the number of graphics processors), it is often necessary to use a model such as the FP8 and other lower-precision formats, which may require a trade-off between performance and feasibility.
Breaking down hardware barriers: making AI more accessible
While Gemma 3 performs well on high-end hardware for cloud deployments and research scenarios, user feedback clearly indicates that the market expects to utilize Gemma 3's capabilities on existing hardware. Driving the adoption of powerful AI technologies means that models need to be made to run efficiently on consumer GPUs commonly found in desktops, laptops, and even mobile devices. Running large models locally not only enhances data privacy, reduces network latency, and supports offline applications, but also provides more room for user customization.
QAT Technology: The Key to Balancing Performance and Accessibility
Quantization techniques are key to achieving this goal. In AI models, quantization aims to reduce the precision of the numbers (i.e., model parameters) used in model storage and computation. This is similar to compressing an image by reducing the number of colors used in the image. Compared to using 16 bits per number (BF16), quantization can use fewer bits, such as 8 bits (int8) or even 4 bits (int4).
adoption int4 This means that each digit is represented by only 4 bits, and the data size is much smaller than the BF16 Reduced by a factor of 4. Traditional quantization methods (e.g., post-training quantization PTQ) are usually performed after the model has been trained, which is easy to implement but can lead to significant performance degradation. The QAT technique used by Google is different.
QAT introduces a quantization step right during model training to simulate low-precision operations. This approach allows the model to adapt to the low-precision environment while still in training, which in turn allows for better accuracy retention during subsequent quantization, enabling smaller, faster models. Specifically, Google applied approximately 5,000 steps of QAT to the Gemma 3 model, targeting the probability of an unquantized checkpoint. In this way, it is claimed that after quantizing to Q4_0 The decrease in perplexity, a measure of the model's predictive power, is reduced by 54% when the format (using the llama.cpp (Assessment).
Significant effect: VRAM usage reduced dramatically
int4 The impact of quantization is significant, especially in terms of the amount of video memory (VRAM) required to load the model weights:
- Gemma 3 27B. From 54 GB (
BF16) to 14.1 GB (int4) - Gemma 3 12B. From 24 GB (
BF16) Reduction to 6.6 GB (int4) - Gemma 3 4B. From 8 GB (
BF16) Reduced to 2.6 GB (int4) - Gemma 3 1B. From 2 GB (
BF16) to 0.5 GB (int4)

Caution. This data represents only the VRAM required to load the model weights. running the model also requires additional VRAM for the KV cache, which stores dialog context information, the size of which depends on the context length.
Run Gemma 3 on your device!
The dramatic reduction in graphics memory requirements makes it possible to run larger, more powerful models on widely available consumer-grade hardware:
- Gemma 3 27B (
int4): Now it's easy to run on a single 24GB VRAM desktop classNVIDIA RTX 3090or similar graphics cards, users were able to run Google's largest Gemma 3 variant locally. - Gemma 3 12B (
int4): The ability to run on laptop GPUs with 8GB of VRAM (such as theNVIDIA RTX 4060 Laptop GPUThe company also brings powerful AI capabilities to portable devices. - Smaller models (4B, 1B). Provides greater accessibility to more resource-constrained systems, including some mobile devices.
Easy integration with mainstream tools
To make it easier for users to use these models in their own workflows, Google has made the Hugging Face cap (a poem) Kaggle The official int4 cap (a poem) Q4_0 Unquantized QAT models. At the same time, Google has partnered with several popular developer tools to allow users to seamlessly try out QAT-based quantization checkpoints:
- Ollama. Quick to run with a simple command, all Gemma 3 QAT models are natively supported.
- LM Studio. Provides a user-friendly interface to easily download and run Gemma 3 QAT models on your desktop.
- MLX. utilization
MLXThe framework is inApple SiliconEfficient and optimized inference of Gemma 3 QAT models on the - Gemma.cpp. A specialized C++ implementation from Google for efficient inference on the CPU.
- llama.cpp. Native support for QAT models in GGUF format for easy integration into existing workflows.
More Quantization Options in the Gemmaverse Ecology
In addition to the officially published QAT model, active Gemmaverse The community also offers many alternative programs. These programs typically use post-training quantization (PTQ) techniques, which are used by the Bartowski, Unsloth, GGML and other community member contributions, and in Hugging Face Available on. Exploring these community options provides users with a wider range of choices for tradeoffs between model size, speed, and quality to meet specific needs.
Start your experience now!
Bringing cutting-edge AI performance to easily accessible hardware is a critical step in democratizing AI development. With Gemma 3 models optimized through QAT, users can now leverage cutting-edge AI capabilities on their own desktop or laptop. This not only lowers the barriers for developers and researchers to explore large-scale language models, but also heralds the potential for more powerful edge AI applications.
Explore quantitative models and start building them:
- Use on a PC
OllamaRunning:https://ollama.com/library/gemma3 - exist
Hugging Facecap (a poem)KaggleLook up the model on: - Running on a mobile device (via
Google AI Edge):https://developers.googleblog.com/en/gemma-3-on-mobile-and-web-with-google-ai-edge/