General Introduction
NodeRAG is an open source Retrieval Augmented Generation (RAG) system hosted on GitHub and developed by Terry-Xu-666, which optimizes information retrieval and generation through heterogeneous graph structures to significantly improve retrieval accuracy and context relevance. It optimizes information retrieval and generation through heterogeneous graph structures, significantly improving retrieval accuracy and contextual relevance.NodeRAG supports local deployment, and provides user-friendly interfaces and visualization tools for academic research, knowledge management, and data analysis. The first stable version (v0.1.0) will be released in March 2025, and can be installed via PyPI. The official documentation is thorough, and the community is active and up-to-date. Compared to traditional RAG system, NodeRAG performs better in multi-hop reasoning, retrieval speed and storage efficiency, and is especially suitable for processing complex datasets.

Function List
- Heterogeneous graph structure: supports multiple node types (e.g., documents, entities, keywords) to improve retrieval accuracy.
- Accurate search: multi-hop reasoning and context-sensitive queries are supported through graph decomposition, augmentation, enrichment and search.
- Data Visualization: Provides interactive graph structure visualization for easy understanding of complex data relationships.
- Local Deployment Interface: Supports local operation and provides an intuitive user interaction experience.
- Cross-platform installation: Supports Conda, Docker and PyPI installations, compatible with multiple environments.
- Incremental update: Supports dynamic updating of the graph structure without rebuilding the entire graph database.
- High-performance optimization: fast indexing and querying for large-scale dataset processing.
- Open Documentation: Provides detailed tutorials, sample code and academic papers for easy learning.
Using Help
Installation process
NodeRAG supports a variety of installation methods. The following describes the steps for installing via Conda and PyPI. Ensure that Python 3.10 or later is installed on your system.
1. Installation via Conda
- Creating a Virtual Environment
Open a terminal and run the following command to create and activate a Conda environment:conda create -n NodeRAG python=3.10 conda activate NodeRAG
- Clone code base (optional)
If you need the source code or a development version, you can clone it from GitHub:git clone https://github.com/Terry-Xu-666/NodeRAG.git cd NodeRAG - Installation of dependencies
In the project directory, run the following command to install the dependencies:pip install -r requirements.txtDependencies include
networkx(Figure operation),numpy(numerical calculations),flask(Web interface), etc. - Installing NodeRAG
If you have not cloned the code base, you can install it directly from PyPI:pip install NodeRAG - Running the Local Interface
Run the following command to start the local web interface:python -m NodeRAG.appOpen your browser and visit
http://localhost:5000The NodeRAG interface is accessible.
2. Accelerated installation with uv (optional)
To increase the speed of installation, use the uv Tools:
- mounting
uv::pip install uv - utilization
uvInstall NodeRAG:uv pip install NodeRAG
3. Verification of installation
After launching the interface, load the officially provided example dataset (located in the data/sample catalog or online documentation), check if the diagram visualization is displayed correctly. If you have any problems, please refer to the official FAQ.
Using the main functions
The core of NodeRAG lies in the construction, retrieval and generation of heterogeneous graphs. The following describes the operation process in detail.
1. Constructing heterogeneous maps
NodeRAG uses a heterogeneous graph to store data, and node types include document, entity, keyword, etc. Users need to prepare data in JSON or CSV format, containing text and metadata (e.g. title, author). Procedure:
- Log in to the web interface and click "Data Import".
- Select the data file and set the node type (e.g., "Document") and edge relationship (e.g., "Document-Keyword").
- Click "Build Diagram", the system generates the diagram structure and saves it to the local database.
Example: import academic paper dataset, the system extracts titles, authors, keywords and generates knowledge graph.
2. Executive information retrieval
The retrieval of NodeRAG is based on a graph search algorithm and supports multi-hop reasoning. Operation Steps:
- Enter a query in the interface, such as "Deep Learning in Healthcare".
- Select the depth of search (2-3 hops recommended) and click "Search".
- The system returns relevant nodes, edges, and paths that demonstrate contextual relationships.
- The results are presented as a list and graph, and users can click on nodes to view details.
The search supports complex queries such as multi-criteria combinations or cross-field searches.
3. Content generation
NodeRAG generates context-sensitive answers in conjunction with the Big Model. Operational Steps:
- On the search results screen, click "Generate Answer".
- The system generates text based on the retrieved nodes by invoking the big model.
- User adjustable parameters (e.g.
temperature,max_tokens) controls the output style.
Example: The query "Recent advances in quantum computing" generates an answer that includes recent research developments.
4. Data visualization
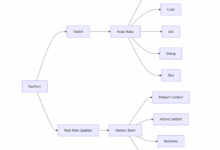
NodeRAG provides interactive graph visualization tools to help users visually analyze data relationships. Operation Steps:
- Select "Graph Visualization" in the interface.
- The system displays the nodes and edges of the graph and supports zooming, dragging and filtering.
- Click on a node to see the attributes (e.g., text content), and click on an edge to see the relationship type.
This feature is suitable for exploring complex datasets such as knowledge graphs and social networks.
5. Incremental update
NodeRAG supports dynamic updating of the graph structure without rebuilding the entire graph. Operation Steps:
- Select "Incremental Update" on the screen.
- Upload new data files and the system automatically integrates them into the existing diagram structure.
- After updating, rerun the query to verify the results.
This feature is suitable for continuous updating scenarios such as news databases or corporate document repositories.
6. Customized configuration
Advanced users can edit the config.yaml The file adjusts the graph structure and algorithm parameters, such as node weights, edge types, and retrieval depth. After modification, run the following command to reload:
python -m NodeRAG.reload_config
Featured Function Operation
The heterogeneous graph structure of NodeRAG is its core strength, optimizing retrieval and generation through the following four steps:
- graphical decomposition : Split complex queries into subtasks and assign them to different node types.
- graphical enhancement : Complementary implicit relationships between nodes to improve contextual integrity.
- Chart enrichment : Integrate external knowledge (e.g., publicly available datasets) into the graph.
- image search : Fast localization of relevant nodes using efficient algorithms.
Operational Steps: - Enable "Graph Enhancement" or "Graph Enrichment" in the "Advanced Settings" section of the interface.
- After entering a query, the system automatically applies these steps to generate more accurate results.
These features significantly enhance multi-hop reasoning and are suitable for complex problem analysis.
Frequently Asked Questions
- installation failure : Check Python version (3.10+ required) and network connection. Use a domestic mirror source to speed up installation:
pip install NodeRAG -i https://pypi.tuna.tsinghua.edu.cn/simple
- The interface is inaccessible : Acknowledgement
NodeRAG.appis running, check if port 5000 is occupied. - Inaccurate search results : Optimize input data (ensure metadata is complete), or increase search depth.
- Large Model Integration Issues : in
config.yamlThe model API or local model path is correctly configured in the
More questions can be found in the official documentation:NodeRAG_web.
supplementary note
- Data preparation : Input data should be structured, JSON format is recommended, containing
content(text) andmetadata(metadata) field. - performance optimization : NodeRAG uses a unified algorithm and indexing mechanism, and query response times are typically in the second range, even when dealing with large-scale datasets.
- Community Support : The GitHub repository provides an Issues page where users can submit issues or participate in discussions.
application scenario
- academic research
Researchers can use NodeRAG to organize the literature data and construct a thesis relationship graph. After importing the thesis dataset, the system extracts keywords, authors, and citation relationships to generate a knowledge graph. Users can query the research topic, get related literature and contextual analysis, suitable for literature review or topic planning. - Enterprise Knowledge Management
Enterprises can use NodeRAG to manage internal documents and build a knowledge base. After importing technical documents and project reports, the system generates a document relationship diagram. Employees can quickly search for information to improve knowledge sharing efficiency, suitable for technical teams or cross-departmental collaboration. - Data Analysis and Visualization
Data analysts can use NodeRAG to analyze complex datasets such as social network or customer relationship data. The system helps discover hidden patterns by visualizing data connections through graphs, and is suitable for market analysis, risk assessment, or recommender system development. - Real-time information processing
NodeRAG's incremental update feature is suitable for handling dynamic data such as news or social media content. Users can continuously import new data and the system automatically updates the graph structure to keep search results current.
QA
- What data formats does NodeRAG support?
JSON, CSV and TXT formats are supported. JSON is recommended and requires the inclusion ofcontent(text) andmetadata(e.g., author, date) fields. - How to improve search accuracy?
Ensure that the data contains rich meta-information, enable graph enhancement or graph enrichment, and increase the depth of search as appropriate (2-3 hops). - Does NodeRAG support live updates?
Supports incremental updates, users can upload new data to dynamically update the graph structure without rebuilding the entire graph. - Is large model support required?
NodeRAG can be integrated with LLaMA, GPT and other models. Requires the use of theconfig.yamlConfigure the model API or local path in the - How do I view performance benchmarks?
The official documentation provides performance comparison charts to demonstrate the benefits of NodeRAG in terms of retrieval quality and speed, see NodeRAG_web.