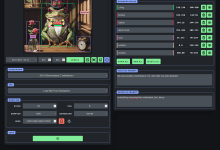
General Introduction ChatTTS is a generative speech model designed for conversational scenarios. It generates natural and expressive speech, supports multiple languages and multiple speakers, and is suitable for interactive conversations. The model goes beyond large by predicting and controlling fine-grained prosodic features such as laughter, pauses, and interjections...
Comprehensive Introduction MoneyPrinterPlus is an open source project aimed at generating and mixing all kinds of short videos with one click through AI technology, and automatically publishing them to multiple video platforms, such as Jieyin, Shutterbugs, Xiaohongshu, and Video Number. The tool supports local and cloud-based voice models, including chatTTS, fasterwhisper, G...
Enable Builder Smart Programming Mode, unlimited use of DeepSeek-R1 and DeepSeek-V3, smoother experience than the overseas version. Just enter the Chinese commands, even a novice programmer can write his own apps with zero threshold.
Comprehensive Introduction TF-ID (Table/Figure IDentifier) is a family of object detection models specialized for extracting tables and images from academic papers. The project was created by Yifei Hu and open-sourced on GitHub.TF-ID models are fine-tuned to recognize and extract tables and images from academic papers...
General Introduction Chatbot UI is an open source project designed to help developers create personalized and intelligent conversational interfaces. The project provides a range of interface components and interactive features that can be easily integrated into the existing Chatbot system to provide users with a smoother and smarter conversation experience.Chatbot UI ...
General Introduction GLIGEN GUI is an intuitive graphical interface based on ComfyUI designed to simplify the use of the GLIGEN model, a novel text-to-image model that allows precise specification of the position of objects in an image. With GLIGEN GUI, the user is prompted by drawing boxes and entering text...
Comprehensive Introduction Easy-Voice-Toolkit is a multifunctional toolkit based on the Open Source Speech Project that provides a wide range of automated audio tools for speech recognition, speech transcription, speech conversion, dataset creation and model training. Users can use these tools selectively or sequentially as needed...
General Introduction FaceFusion is an advanced cloud platform with integrated facial exchange and enhancement features that optimizes the image-to-video and image-to-image exchange process with 5 professional models to ensure flawless output. In addition, it performs facial enhancement with 7 models, using 3 different models to boost...
General Introduction Kotaemon is an open source document Q&A tool designed to provide end-users and developers with Q&A capabilities based on Retrieval Augmented Generation (RAG). Developed by Cinnamon, the project supports a variety of LLM API providers (e.g. OpenAI, AzureOpenAI, Cohere, etc.) as well as native...
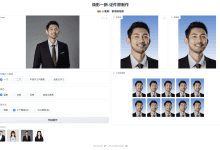
Comprehensive introduction HivisionIDPhotos is an open source lightweight AI document photo production tools, can intelligently identify the user photo scene and keying, to generate a standard document photo in line with a variety of specifications. The tool supports custom background colors and sizes, and in the future will also launch the beauty and intelligent change of formal dress function. With...
General Introduction Marker is a deep learning based document processing tool designed to convert PDF files to Markdown format quickly and accurately. It supports a wide range of document types and is especially optimized for conversion of books and scientific papers.Marker is able to remove redundant content such as headers and footers, format tables and...
General Introduction SadTalker is an open source tool that combines single still portrait photos and audio files to create realistic talking head videos for a wide range of scenarios such as personalized messages, educational content, and more. The revolutionary use of 3D modeling technologies such as ExpNet and PoseVAE excel in capturing the subtle facets...
General Introduction VideoReTalking is an innovative system that allows users to generate lip-synchronized facial videos based on input audio, producing high-quality and lip-synchronized output videos even with different emotions. The system breaks down this goal into three successive tasks: facial video generation with typical expressions...
General Introduction MuseV is a public project on GitHub that aims to enable the generation of avatar videos of unlimited length and high fidelity. It is based on diffusion technology and offers Image2Video, Text2Image2Video, Video2Video and many other features. Provides model structure, use cases, quick start...
Comprehensive Introduction Unstructured-IO provides a range of open source components for processing and preprocessing images and text documents such as PDF, HTML, Word documents, etc. Its main goal is to simplify and optimize data processing workflow , especially for large language model (LLM) applications to provide support.Unstructured...
General Introduction magic-html is a Python library designed to simplify the process of extracting body region content from HTML. Whether dealing with complex HTML structures or simple web pages, this library aims to provide a convenient and efficient interface for users. It supports multimodal extraction, multiple layout extracto...
WebPilot General Introduction Webpilot is a free and open source "web assistant" that allows you to communicate freely with any web page or perform automated tasks. Instead of switching pages or copying and pasting, just select text or enter commands, and webpilot will provide you with real-time information and smart...
Comprehensive Introduction DB-GPT is an open source AI native data application development framework built using AWEL (Agentic Workflow Expression Language) and intelligent body technologies. The project aims to build infrastructure in the field of large models by developing several technical capabilities, including a multi-model management system (SMMF),...
DreamTalk Comprehensive Introduction DreamTalk is a diffusion model-driven expression talking head generation framework, jointly developed by Tsinghua University, Alibaba Group and Huazhong University of Science and Technology. It is mainly composed of three parts: a noise reduction network, a style-aware lip expert and a style predictor, and is able to generate a variety of audio input based on...
Comprehensive Introduction InstantID is an advanced technology focused on generating images with personalized styles or poses in seconds while ensuring a high level of fidelity using a single reference ID image. The technology employs a diffusion model-based solution by integrating facial images, landmark images with...