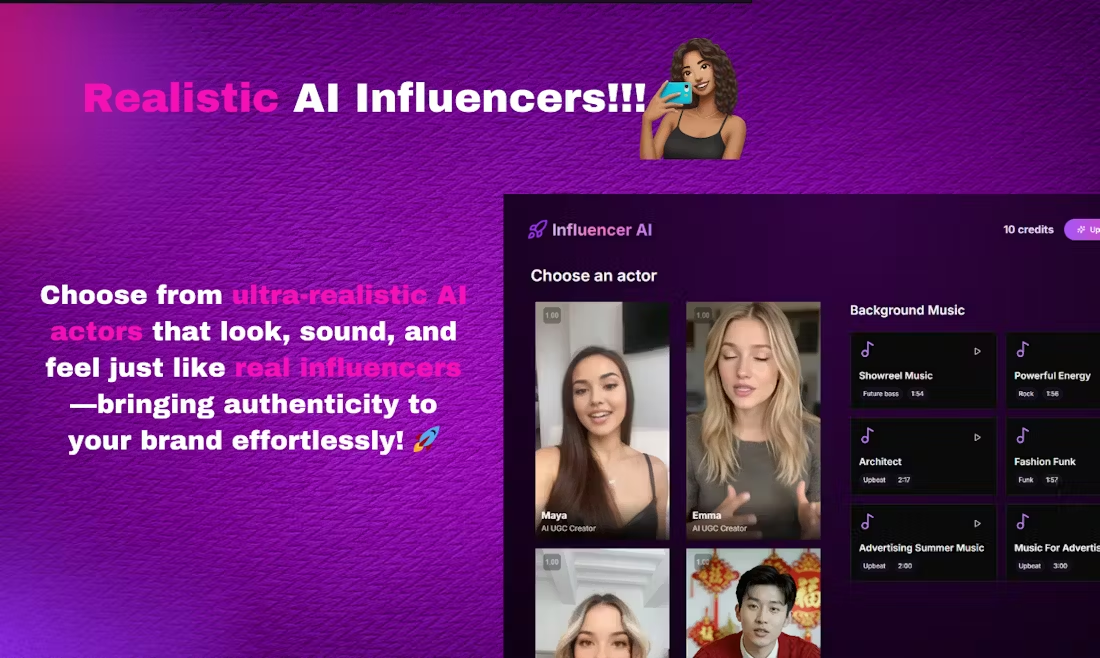

综合介绍
FantasyTalking 是一个由 Fantasy-AMAP 团队开发的开源项目,专注于通过音频驱动生成真实感说话肖像视频。项目基于先进的视频扩散模型 Wan2.1,结合音频编码器 Wav2Vec 和专有模型权重,利用人工智能技术实现高度逼真的唇部同步和面部表情。它支持多种风格的肖像生成,包括真实人物和卡通形象,适用于全景、半身或特写等多种视角。用户可以通过简单的命令行操作,输入图像和音频,快速生成高质量的说话视频。

功能列表
- 生成真实感说话肖像视频,唇部动作与音频高度同步。
- 支持多种视角生成,包括特写、半身和全身肖像。
- 兼容真实和卡通风格的肖像,满足多样化需求。
- 提供提示词控制功能,调整角色表情和肢体动作。
- 支持高分辨率输出,最高可达720P。
- 集成面部专注交叉注意力模块,确保面部特征一致性。
- 包含运动强度调制模块,控制表情和动作幅度。
- 开源模型和代码,支持社区二次开发和优化。
使用帮助
安装流程
要使用 FantasyTalking,需要先安装必要的依赖和模型。以下是详细的安装步骤:
- 克隆项目代码
在终端运行以下命令,将项目克隆到本地:git clone https://github.com/Fantasy-AMAP/fantasy-talking.git cd fantasy-talking
- 安装依赖
项目依赖 Python 环境和 PyTorch(版本需 >= 2.0.0)。运行以下命令安装所需库:pip install -r requirements.txt可选安装
flash_attn以加速注意力计算:pip install flash_attn - 下载模型
FantasyTalking 需要三个模型:Wan2.1-I2V-14B-720P(基础模型)、Wav2Vec(音频编码器)和 FantasyTalking 模型权重。可以通过 Hugging Face 或 ModelScope 下载:- 使用 Hugging Face CLI:
pip install "huggingface_hub[cli]" huggingface-cli download Wan-AI/Wan2.1-I2V-14B-720P --local-dir ./models/Wan2.1-I2V-14B-720P huggingface-cli download facebook/wav2vec2-base-960h --local-dir ./models/wav2vec2-base-960h huggingface-cli download acvlab/FantasyTalking fantasytalking_model.ckpt --local-dir ./models - 或者使用 ModelScope CLI:
pip install modelscope modelscope download Wan-AI/Wan2.1-I2V-14B-720P --local_dir ./models/Wan2.1-I2V-14B-720P modelscope download AI-ModelScope/wav2vec2-base-960h --local_dir ./models/wav2vec2-base-960h modelscope download amap_cvlab/FantasyTalking fantasytalking_model.ckpt --local_dir ./models
- 使用 Hugging Face CLI:
- 验证环境
确保 GPU 可用(推荐 RTX 3090 或更高,VRAM 至少 24GB)。如果遇到内存问题,可尝试降低分辨率或启用 VRAM 优化。
使用方法
安装完成后,用户可以通过命令行运行推理脚本生成视频。基本命令如下:
python infer.py --image_path ./assets/images/woman.png --audio_path ./assets/audios/woman.wav
--image_path:输入肖像图像路径(支持 PNG/JPG 格式)。--audio_path:输入音频文件路径(支持 WAV 格式)。--prompt:可选提示词,用于控制角色行为,例如:--prompt "The person is speaking enthusiastically, with their hands continuously waving."--audio_cfg_scale和--prompt_cfg_scale:控制音频和提示词的影响程度,推荐范围为 3-7。提高音频 CFG 可增强唇部同步效果。
特色功能操作
- 唇部同步生成
FantasyTalking 的核心功能是基于音频生成精准的唇部动作。用户需准备清晰的音频文件(如 WAV 格式,16kHz 采样率最佳)。运行推理脚本后,模型会自动分析音频并生成匹配的唇部动作。确保音频无明显噪音,以获得最佳效果。 - 提示词控制
通过--prompt参数,用户可以定义角色的表情和动作。例如,输入--prompt "The person is speaking calmly with slight head movements."可生成平静的说话视频。提示词需简洁明确,避免模糊描述。 - 多风格支持
项目支持真实和卡通风格的肖像生成。用户可提供不同风格的输入图像,模型会根据图像特征调整输出风格。卡通风格适合动画场景,真实风格适合虚拟主播等应用。 - 运动强度调制
FantasyTalking 的运动强度调制模块允许用户控制表情和动作的幅度。例如,设置较高的--audio_weight参数可增强肢体动作,适合动态场景。默认设置已优化,建议初次使用时保持默认值。
注意事项
- 硬件要求:生成高分辨率视频需要强大 GPU。32GB VRAM 的 RTX 5090 可能仍会遇到内存不足问题,建议降低
--image_size或--max_num_frames。 - 模型下载:模型文件较大(约几十 GB),确保网络稳定和足够磁盘空间。
- 提示词优化:提示词对输出影响较大,建议多次实验以找到最佳描述。
应用场景
- 虚拟主播内容创作
用户可以利用 FantasyTalking 为虚拟主播生成逼真的说话视频。输入主播的肖像图像和配音音频,生成唇部同步的视频,适用于直播、短视频或教育内容制作。 - 动画角色配音
动画制作者可为卡通角色生成配音视频。提供卡通形象和音频,模型能生成匹配的唇部动作和表情,简化动画制作流程。 - 教育视频制作
教师或培训机构可生成虚拟讲师视频。输入讲师肖像和课程音频,快速生成教学视频,增强内容吸引力。 - 娱乐和迷因创作
用户可为迷因或娱乐视频生成搞笑的说话肖像。通过调整提示词,制作夸张表情或动作的视频,适合社交媒体分享。
QA
- FantasyTalking 支持哪些输入格式?
图像支持 PNG 和 JPG 格式,音频支持 WAV 格式,推荐 16kHz 采样率以获得最佳唇部同步效果。 - 如何解决显存不足问题?
如果 GPU 显存不足(如 RTX 5090 的 32GB VRAM),可降低--image_size(如 512x512)或减少--max_num_frames(如 30 帧)。也可启用 VRAM 优化选项或使用更高配置的 GPU。 - 生成的视频质量如何提高?
使用高分辨率输入图像(至少 512x512),确保音频清晰无噪音。调整--audio_cfg_scale(如 5-7)可增强唇部同步,优化提示词可提升表情自然度。 - 是否支持实时生成?
当前版本仅支持离线推理,实时生成需进一步优化模型和硬件支持。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...