

大規模な言語モデリング技術の急速な発展と幅広い応用に伴い、その潜在的なセキュリティリスクはますます業界の注目の的となっています。このような課題に対処するため、世界中の多くのトップ技術企業、標準化団体、研究機関が独自のセキュリティフレームワークを構築し、公開しています。本稿では、関連分野の実務者に明確な参考情報を提供することを目的として、代表的な9つの大規模モデルのセキュリティフレームワークを整理し、分析する。

図:ビッグモデルのセキュリティ・フレームワークの概要
グーグルのセキュアAIフレームワーク(SAIF)(リリース2025.04)
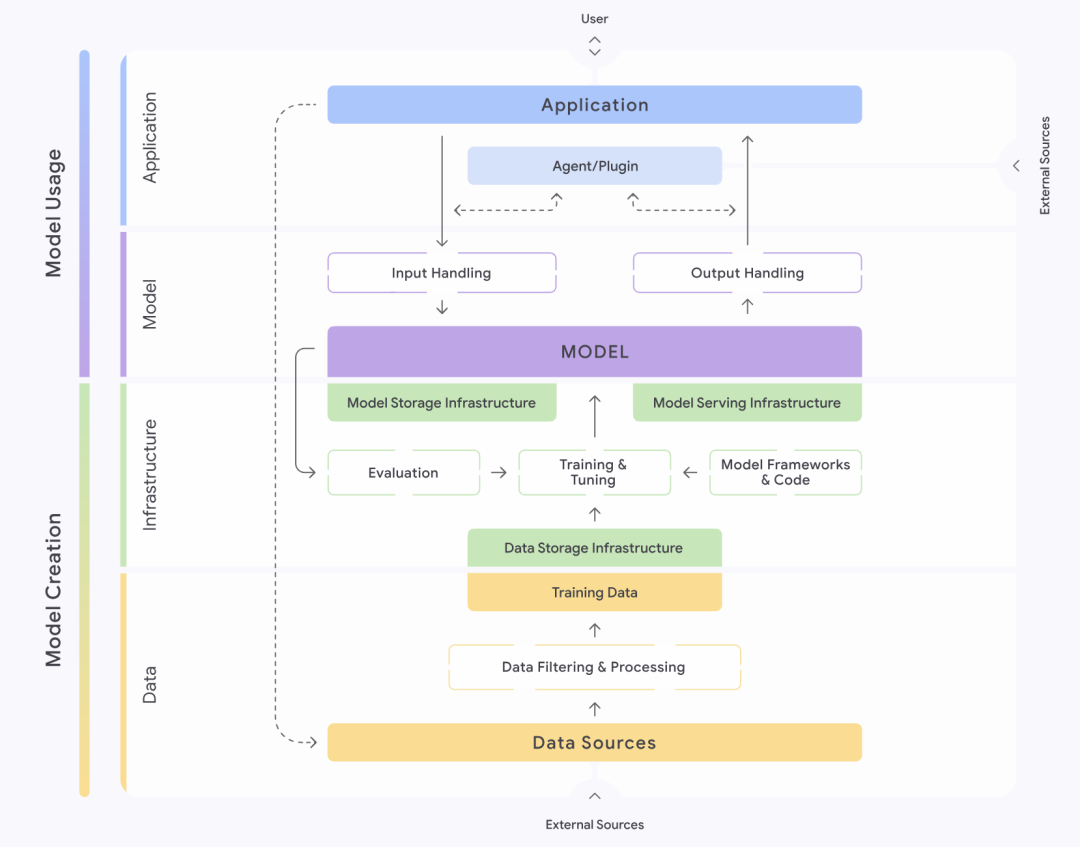
図:Google SAIFのフレームワーク構造
グーグル(Google)が導入したセキュアAIフレームワーク(SAIF)は、AIシステムのセキュリティを理解し管理するための構造化されたアプローチを提供する。このフレームワークは、AIシステムをデータ、インフラ、モデル、アプリケーションの4つのレイヤーに緻密に分割している。各レイヤーはさらに、データ・ソース、データのフィルタリングと処理、トレーニング・データなどの重要な部分を含むデータ・レイヤーのような、異なるコンポーネントに分解される。
SAIFは、AIシステムの完全なライフサイクルに基づき、データポイズニング、学習データへの不正アクセス、モデルソースの改ざん、過剰なデータ処理、モデル漏洩、モデル展開の改ざん、モデルDoS、モデルリバースエンジニアリング、安全でないコンポーネント、キューワードインジェクション、モデルスクランブル、機密データ漏洩、外挿による機密データアクセス、安全でないモデル出力、悪意のある行動を含む15の主要なリスクを特定し、選別する。モデル出力、悪意のある行動などである。これら15のリスクに対応して、SAIFは15の予防策と管理策も提案しており、これが中核的なセキュリティガイダンスを構成している。
OWASPによるビッグモデルアプリケーションのセキュリティ脅威トップ10(2025.03公開)

図:OWASPビッグモデルアプリケーションのセキュリティ脅威トップ10
OWASPは、ビッグモデル・アプリケーションを、ビッグモデル・サービス自体、サードパーティの機能、プラグイン、プライベートなデータベース、外部のトレーニングデータなど、いくつかの重要な「信頼ドメイン」に分解しています。 OWASPは、ビッグモデル・アプリケーションを、ビッグモデル・サービス自体、サードパーティの機能、プラグイン、外部のトレーニングデータなど、いくつかの重要な「信頼ドメイン」に分解しています。プラグイン、プライベートデータベース、外部トレーニングデータなどである。OWASPは、これらの信頼ドメイン間の相互作用と信頼ドメイン内の相互作用の両方において、多くのセキュリティ脅威を特定している。
OWASPの最も重要なセキュリティ脅威のトップ10は、影響の大きい順に、「プロンプト・インジェクション」、「機密情報漏洩」、「サプライチェーン・リスク」、「データとモデルの汚染」、「不適切な出力処理」、「過剰な権限付与」、「システム・プロンプト漏洩」、「ベクターと埋め込み脆弱性」、「誤解を招く情報」、「無制限のリソース消費」です。これらの脅威のそれぞれについて、OWASP は予防と制御のための勧告を提示しており、開発者とセキュリティ担当者に実用的な指針を提供している。
OpenAIのモデルセーフティフレームワーク(継続更新中)
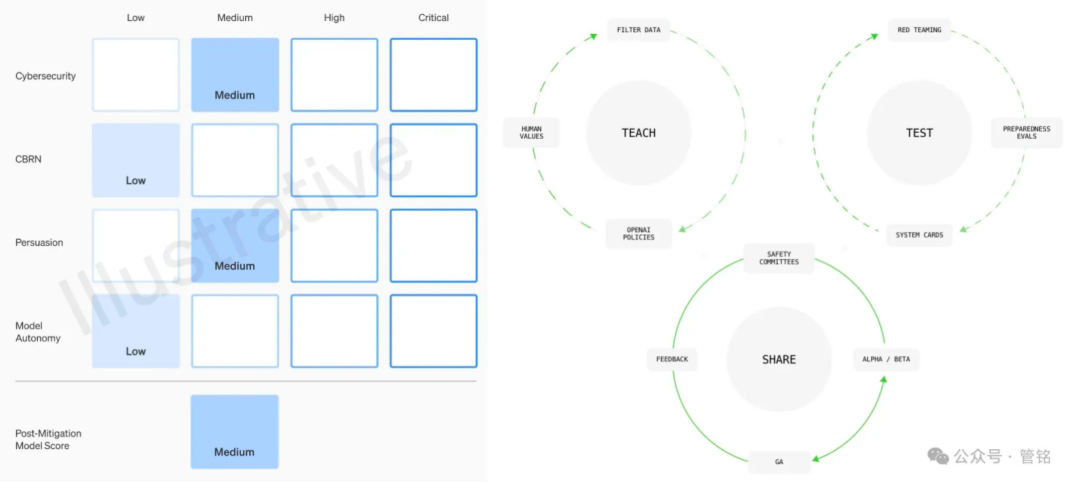
図:OpenAIモデルのセキュリティ・フレームワークの次元
ビッグモデル技術のリーダーとして、OpenAIはモデルのセキュリティに高い優先順位を置いている。そのモデルのセキュリティフレームワークは、大量破壊兵器(CBRN)リスク、サイバー攻撃能力、説得力(人間の意見や行動に影響を与えるモデルの能力)、モデルの自律性という4つの次元に基づいており、潜在的な危害のレベルに応じて、低、中、高、重度のいずれかに分類されます。各モデルのリリース前には、この枠組みに基づいて、システムカードと呼ばれる詳細なセキュリティ評価を提出しなければならない。
さらにOpenAIは、価値観の調整、敵対的評価、制御の反復を含むガバナンスの枠組みを提案している。価値観の調整フェーズでは、OpenAIは普遍的な人間の価値観と一致する一連のモデル行動を策定し、モデルトレーニングの全フェーズにおけるデータクリーニング作業を指導することを約束する。敵対的評価フェーズでは、OpenAIは専門的なテストケースを構築し、保護措置を講じる前と後のモデルを完全にテストし、最終的にシステムカードを作成します。制御反復フェーズでは、OpenAIはすでに配備されたモデルに対してバッチ起動戦略を採用し、保護措置を追加して最適化し続ける。
サイバーセキュリティ基準委員会のAIセキュリティガバナンスフレームワーク(2024.09公開)
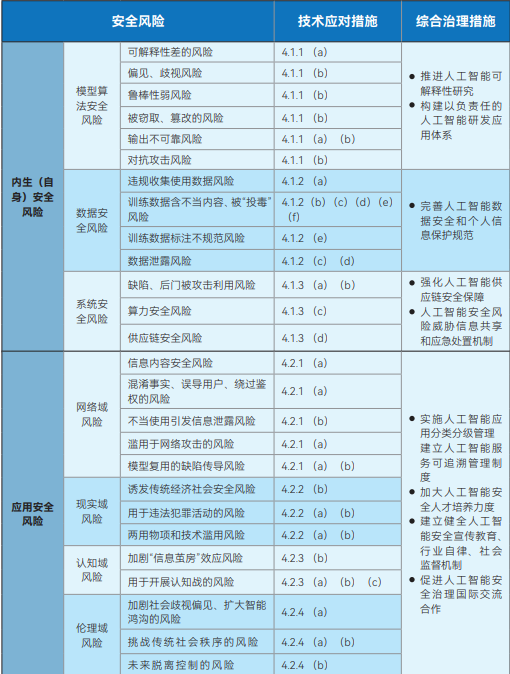
図:ネットセキュリティ標準委員会 AIセキュリティガバナンスフレームワーク
国家サイバーセキュリティ標準化技術委員会(NCSSTC)が発表した人工知能安全ガバナンスフレームワークは、AIの安全な開発のためのマクロガイダンスを提供することを目的としている。同フレームワークでは、AIのセキュリティリスクを内生的(自己)セキュリティリスクとアプリケーションセキュリティリスクの2つに大別している。内生的安全リスクとは、モデル自体に内在するリスクを指し、主にモデルアルゴリズム安全リスク、データ安全リスク、システム安全リスクが含まれる。一方、アプリケーション安全リスクは、モデルがアプリケーションの過程で直面する可能性のあるリスクを指し、さらにネットワーク領域、現実領域、認知領域、倫理領域の4つの側面に細分化される。
これらの特定されたリスクに対して、フレームワークは、モデルやアルゴリズムの開発者、サービス提供者、システム利用者、その他の関係者が、学習データ、演算設備、モデルやアルゴリズム、製品やサービス、応用シナリオなど、様々な側面から積極的に技術的な対策を講じる必要があることを明確に指摘している。同時に、このフレームワークは、技術研究開発機関、サービス提供者、ユーザー、政府部門、業界団体、社会組織などを巻き込んだ、AIセキュリティリスクに対する包括的なガバナンスシステムの確立と改善を提唱している。
サイバーセキュリティ標準委員会 人工知能セキュリティ標準体系 V1.0(2025.01リリース)
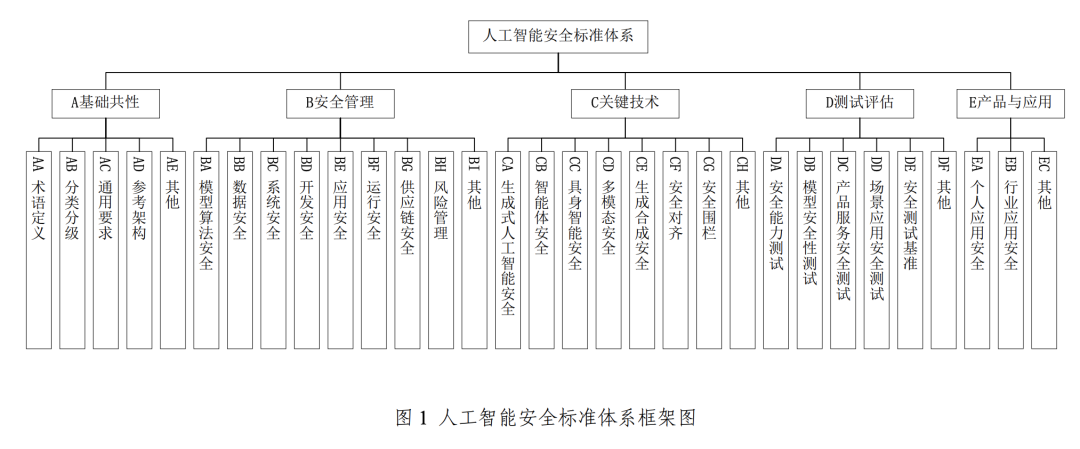
図:ネットセキュリティ標準委員会 人工知能セキュリティ標準システム V1.0
前述の人工知能セキュリティ・ガバナンス・フレームワークを支援・実施するため、中国国家安全保障委員会はさらに「人工知能セキュリティ標準システムV1.0」を立ち上げた。このシステムは、関連する人工知能セキュリティ・リスクの予防と解決に役立つ主要標準を体系的に選別し、サイバーセキュリティに関する既存の国家標準システムとの効果的なインターフェースに重点を置いている。
この標準体系は主に、基本的な共通性、安全管理、主要技術、試験と評価、製品と応用の5つの核心部分から構成されている。このうち、キーとなる安全管理部分は、モデルアルゴリズム安全、データ安全、システム安全、開発安全、アプリケーション安全、運用安全、サプライチェーン安全をカバーしている。一方、キーテクノロジーのセクションでは、生成的AI安全性、知的身体安全性、具現化知能安全性(ロボットなどの物理的実体を持つAIを指し、その安全性は物理的世界との相互作用を伴う)、マルチモーダル安全性、生成的合成安全性、安全アライメント、安全フェンシングなどの最先端分野に焦点を当てている。
清華大学、中関村研究室、アント・グループによるビッグモデル・セキュリティ・プラクティス2024(2024.11リリース)
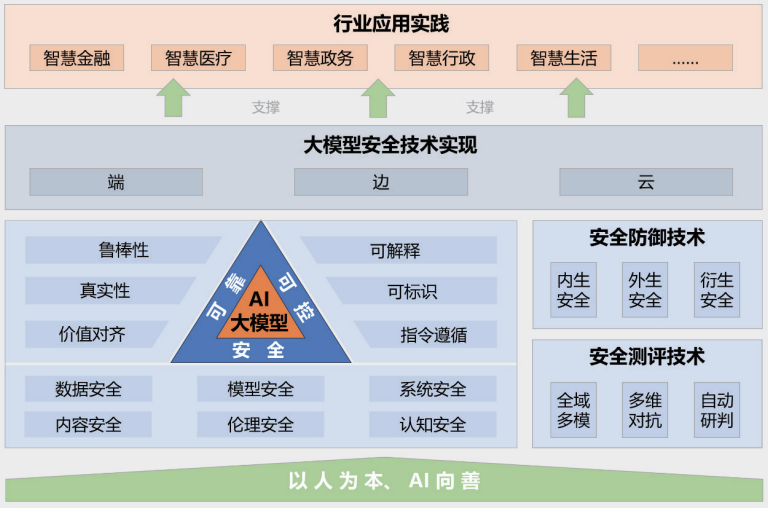
図:2024年ビッグモデル・セキュリティ・プラクティス・フレームワーク
清華大学、中関村研究室、アント・グループが共同で発表した報告書「ビッグモデルセキュリティ実践2024」は、産学と研究の融合という観点からビッグモデルセキュリティに関する洞察を提供している。同報告書で提案されたビッグモデルセキュリティの枠組みは、「人指向、AI for Good」の指導原則、安全で信頼性が高く制御可能なビッグモデルセキュリティ技術システム、セキュリティ測定と防御技術、エンドツーエンド、エッジツーエッジ、クラウド連携セキュリティ技術の実装、多業界における応用実践事例の5つの主要部分から構成されている。
例えば、データ漏洩、データ窃盗、データポイズニング、敵対的攻撃、コマンド攻撃(よく設計されたコマンドによってモデルに意図しない行動を誘発させる)、モデル盗用攻撃、ハードウェアセキュリティの脆弱性、ソフトウェアセキュリティの脆弱性、フレームワーク自体のセキュリティ問題、外部ツールによってもたらされるセキュリティリスク、有害コンテンツの生成、偏ったコンテンツの流布、偽情報の生成、イデオロギーリスク、通信詐欺と個人情報窃盗、知的財産権と著作権の侵害、教育産業における完全性の危機、偏見に起因する公平性の問題などである。イデオロギー的リスク、通信詐欺となりすまし、知的財産と著作権の侵害、教育産業における誠実さの危機、偏見に起因する公正さの問題などである。また、これらの複雑なリスクに対処するための防御技術も提案している。
アリユンとICTAによるビッグモデルセキュリティ調査レポート(2024.09発行)
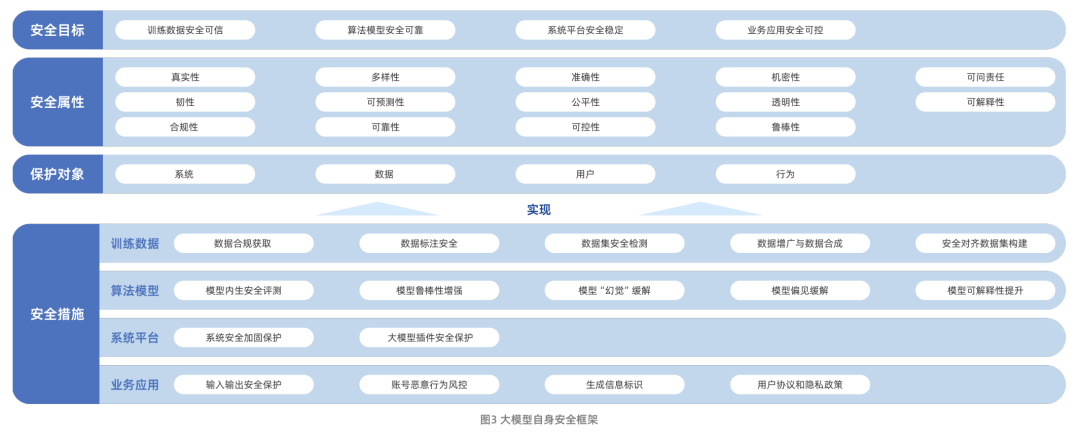
図:アリユン&ICTAビッグモデルセキュリティ調査報告書フレームワーク
阿里雲と中国情報通信技術研究院(CAICT)が共同で発表した「ビッグモデルセキュリティ研究報告」は、ビッグモデル技術の進化の道筋と、現在直面しているセキュリティ上の課題を体系的に説明している。これらの課題には主に、データセキュリティリスク、アルゴリズムモデルセキュリティリスク、システムプラットフォームセキュリティリスク、ビジネスアプリケーションセキュリティリスクが含まれる。この報告書は、ビッグモデルセキュリティの研究範囲を、モデル自体のセキュリティから、従来のネットワークセキュリティ保護能力を強化・強化するためにビッグモデル技術をどのように利用するかにまで広げていることは注目に値する。
モデル自身のセキュリティに関して、報告書は、セキュリティ目標、セキュリティ属性、保護対象、セキュリティ対策の4つの次元を含むフレームワークを構築している。このうち、セキュリティ対策は、トレーニングデータ、モデルアルゴリズム、システムプラットフォーム、ビジネスアプリケーションの4つの核となる側面を中心としており、全方位的な保護の考え方を反映している。
テンセント研究所のビッグモデル・セキュリティ・エシックス調査2024(2024.01公開)

図:騰訊研究所のビッグモデルセキュリティと倫理研究への懸念
テンセント研究所が発行したレポート「ビッグモデルのセキュリティと倫理に関する調査2024」は、ビッグモデル技術の動向と、これらの動向がセキュリティ業界にもたらす機会と課題について詳細に分析している。同レポートでは、データ漏洩、データポイズニング、モデル改ざん、サプライチェーンポイズニング、ハードウェアの脆弱性、コンポーネントの脆弱性、プラットフォームの脆弱性など15の主要リスクを挙げている。一方、報告書は4つのビッグモデルセキュリティのベストプラクティスを紹介している。迅速なセキュリティ評価、ビッグモデル・ブルーアーミーの攻撃と防御演習、ビッグモデル・ソースコードセキュリティ保護の実践、ビッグモデル・インフラストラクチャの脆弱性セキュリティ保護スキームである。
報告書はまた、ビッグモデルの価値観の調整における進展と今後の動向についても強調している。同報告書は、ビッグモデルの能力や行動が人間の価値観や真意、倫理原則に沿ったものであることをどのように保証し、人間とAIが協働するプロセスにおける安全性と信頼を守るかが、ビッグモデル・ガバナンスの中核的なテーマになっていると指摘している。
360のビッグモデル・セキュリティ・ソリューション(随時更新)
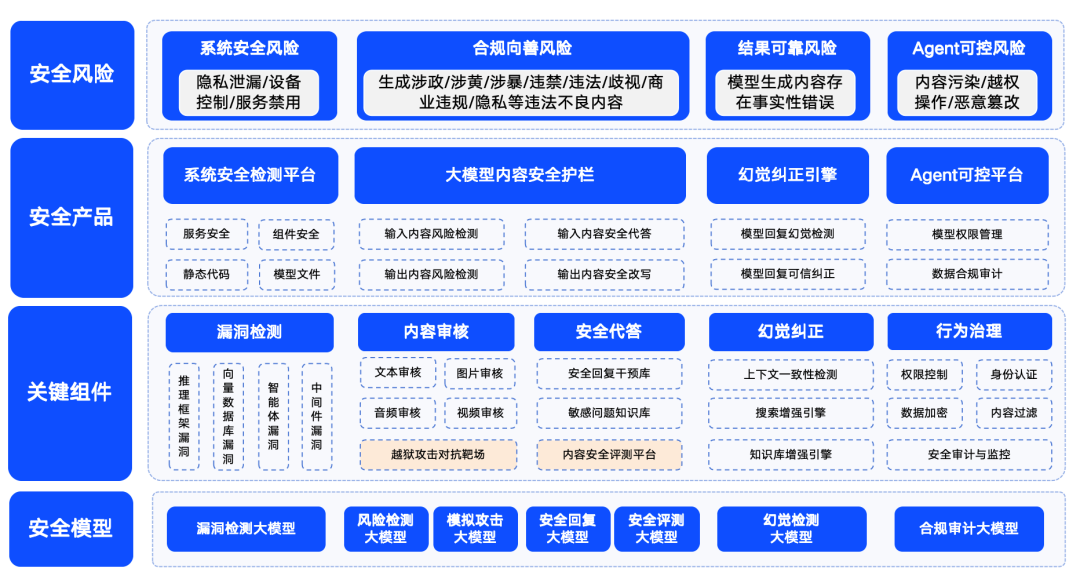
図:360ビッグモデル・セキュリティ・ソリューション概略図
奇虎360は、大型モデルのセキュリティリスクを、システムセキュリティリスク、コンテンツセキュリティリスク、信頼されるセキュリティリスク、制御可能なセキュリティリスクの4つに分類している。このうち、システムセキュリティは、主に、ビッグモデルのエコシステムにおける様々な種類のソフトウェアのセキュリティを指し、コンテンツセキュリティは、入力コンテンツと出力コンテンツのコンプライアンスリスクに焦点を当て、信頼されるセキュリティは、モデルの「錯覚」問題(すなわち、モデルは合理的であるように見えるが現実ではない情報を生成する)の解決に焦点を当て、制御可能なセキュリティは、より複雑なエージェントプロセスのセキュリティ問題を扱う。制御可能なセキュリティは、より複雑なエージェントプロセスのセキュリティ問題を扱います。
360は、大型モデルの安全性、品質、信頼性、制御性を確保し、様々な産業への応用を可能にするため、大型モデル分野における独自の能力の蓄積に基づき、一連の大型モデルセキュリティ製品を構築した。これらの製品には、主にLLMエコシステムの脆弱性を検出することを目的とした「360Smart Forensics」、大型モデルのコンテンツセキュリティに焦点を当てた「360Smart Shield」、信頼できるセキュリティを保証する「360Smart Search」が含まれる。360スマートサーチ」。これらの製品の組み合わせにより、360は早い段階で大型モデル向けの比較的成熟したセキュリティ・ソリューション一式を形成した。













