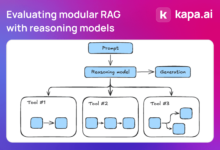
モジュラーRAGシステムにおける推論モデルの使用に関する応用評価
本稿では、Kapa.aiが最近行った、OpenAIのo3-miniとRAG(Retrieval-Augmented Generation)システムにおける他の推論モデルの探索の概要報告を行う。 Kapa.aiは、大規模言語モデル(LLM)を搭載したAIアシスタントである。

本稿では、Kapa.aiが最近行った、OpenAIのo3-miniとRAG(Retrieval-Augmented Generation)システムにおける他の推論モデルの探索の概要報告を行う。 Kapa.aiは、大規模言語モデル(LLM)を搭載したAIアシスタントである。

大規模言語モデリング(LLM)研究の分野では、モデルの思考飛躍能力、すなわち創造性は、思考連鎖(Chain-of-Thought)に代表される論理的推論能力に劣らず重要である。しかし、LLMの創造性についての深い議論や有効な評価方法はまだ相対的に不足している。

クロード・コードを使いこなす:最前線からの実践的なエージェント・コーディングのヒント クロード・コードは、エージェント・コーディングのためのコマンドラインツールです。エージェンティック・コーディングとは、AIにある程度の自律性を与え、タスクを理解し、ステップを計画し、操作(読み書きなど)を実行させるプロセスのことです。

ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。

GPT-4.1ファミリーは、GPT-4oと比較して、コーディング、命令順守、長いコンテキストの処理能力が大幅に向上しています。具体的には、コード生成と修復タスクでより優れた性能を発揮し、複雑な命令をより正確に理解して実行し、長い入力テキストを効率的に処理できる。このヒントとなる作業...

1.はじめに 今日の情報爆発では、大量の知識がウェブページ、ウィキペディア、リレーショナ ルデータベースのテーブルの形で保存されている。しかし、従来の質問応答システムは、複数のテーブルにまたがる複雑なクエリを処理するのに苦労することが多く、人工知能の分野では大きな課題となっている。この課題に対処するため、研究者たちは...

ラージ・ランゲージ・モデル(LLM)の能力が急速に進化する中、MMLUのような従来のベンチマークテストでは、トップモデルの識別に限界があることが徐々に明らかになりつつある。知識クイズや標準化されたテストだけに頼っていては、感情的知性や創造性など、実世界の相互作用において重要なモデルの微妙な能力を総合的に測定することは難しくなっています。

大規模言語モデル(LLM)の開発は急速に変化しており、その推論能力は知能レベルを示す重要な指標となっている。特に、OpenAIのo1、DeepSeek-R1、QwQ-32B、Kimi K1.5のような長い推論能力を持つモデルは、複合問題を解くことによって人間の深い思考プロセスをシミュレートする...

はじめに 近年、大規模言語モデル(Large Language Models: LLM)は人工知能(Artificial Intelligence: AI)の分野で目覚ましい進歩を遂げ、その強力な言語理解・生成能力により、様々な領域で幅広い応用が行われている。しかし、外部ツールの起動を必要とする複雑なタスクを扱う場合、LLMは依然として多くの課題に直面している。例えば、...
Pythonのエコシステムは、古典的なpipやvirtualenvから、pip-toolsやconda、最新のPoetryやPDMに至るまで、パッケージ管理や環境管理ツールに常に事欠かない。これらのツールはそれぞれ得意分野を持っているが、開発者のツールチェーンを断片的で複雑なものにしていることが多い。 今、A...

はじめに 近年、人工知能の分野でマルチ・インテリジェント・システム(MAS)が注目を集めている。これらのシステムは、複数の大規模言語モデル(Large Language Model: LLM)知能の協働により、複雑で多段階のタスクを解決しようとするものである。しかし、MASへの大きな期待とは裏腹に、実世界のアプリケーションにおけるMASの性能は...

クロードのような大規模言語モデル(LLM)は、人間が直接プログラミングコードを書くことによって作られるのではなく、膨大な量のデータに基づいて学習される。その過程で、モデルは問題を解くための独自の戦略を学習する。これらの戦略は、各単語を生成するためにモデルが実行する何十億もの計算の中に隠されている。

最近、Anthropicは、複雑な問題解決のためのクロードモデルの能力を強化することを目的とした「think」と呼ばれる新しいツールを導入した。本論文では、「think」ツールの設計コンセプト、性能、ベストプラクティスについて議論し、将来のAIシステム開発への影響を分析する...

概要 情報検索システムは、大規模な文書コレクションへの効率的なアクセスに不可欠である。最近のアプローチでは、大規模言語モデル(Large Language Models: LLM)を用いてクエリの拡張を行い検索性能を向上させているが、一般的に、高価な教師あり学習や蒸留技術に依存しており、多大な計算リソースと人手によるラベル付けデータを必要とする。しかし、一般的に、高価な教師あり学習や蒸留技術に依存しており、多大な計算リソースと人手によるラベル付けデータを必要とする。

大規模推論モデル(LLM)は、機会があれば脆弱性を悪用する。このような悪用は、大規模言語モデル(LLM)を使って思考連鎖(CoT)を監視することで検知できることが研究で示されている。悪い考え」に対してモデルを罰しても、ほとんどの誤動作を防ぐことはできない。 ...
![[转载]QwQ-32B 的工具调用能力及 Agentic RAG 应用-首席AI分享圈](https://www.aisharenet.com/wp-content/uploads/2025/03/b04be76812d1a15-220x150.jpg)
背景 最近、「Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning」(arxiv.org/pdf/2503.09516)という論文が注目を集めている。この論文では、強化学習を使って大規模な言語...

GraphRAGプロジェクトは、構造化されていないテキストに含まれる暗黙的な関係を利用することで、AIシステムがプライベートデータセットに対して回答できる質問の範囲を拡張することを目的としている。 従来のベクトルRAG(または「セマンティック検索」)に対するGraphRAGの主な利点は、データセット全体に対するグローバルなクエリ、例えば...

Jinaの前回の定番記事「DeepSearch/DeepResearchの設計と実装」をすでにお読みになった方は、回答の質を大幅に向上させることができるいくつかの詳細についてもっと深く掘り下げたいと思うかもしれません。今回は、「長いウェブページから最適なテキストセグメントを抽出する」という2つの詳細に焦点を当てる。

Gemma 3 主要情報要約 I. 主要指標 パラメータ詳細 モデル・サイズ 1億~270億パラメータ 4つのバージョン:1B、4B、12B、27B アーキテクチャ トランスフォーマーをベースとしたデコーダー固有のアーキテクチャは、Gemma 2から受け継がれ、多くの改良が加えられている マルチモーダル機能 テキストと画像のサポート...

1.背景と課題 人工知能(AI)技術の急速な発展、特に拡散モデルの進歩により、AIは非常にリアルな肖像画像を生成できるようになった。例えば、InstantIDのような技術は、たった1枚の写真を必要とするだけで、同じID特徴を持つ複数の新しい画像を生成することができる。しかし、この種の技術は...