知的エージェントによる検索機能強化世代:エージェントRAG技術の概要
概要 OpenAIのGPT-4、GoogleのPaLM、MetaのLLaMAなどの大規模言語モデル(LLM)は、人間のようなテキスト生成と自然言語理解を可能にすることで、人工知能(AI)を劇的に変化させてきた。しかし、静的な学習データに依存しているため、動的でリアルタイムのクエリへの対応には限界がある。

概要 OpenAIのGPT-4、GoogleのPaLM、MetaのLLaMAなどの大規模言語モデル(LLM)は、人間のようなテキスト生成と自然言語理解を可能にすることで、人工知能(AI)を劇的に変化させてきた。しかし、静的な学習データに依存しているため、動的でリアルタイムのクエリへの対応には限界がある。

人工知能(AI)は急速に成長している分野である。言語モデルは、AIエージェントが複雑なタスクを実行し、複雑な意思決定を行えるように進化してきた。しかし、これらのエージェントのスキルが成長し続けるにつれて、それをサポートするインフラは追いつくのに苦労しています。 LangGraphは、AIエージェントに革命を起こすために設計された画期的なライブラリです...

ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。

はじめに 先週リリースされた中国製の大規模言語モデルDeepSeek-R1について、他の多くの人と同様、ここ数日、私のニュースツイートはニュース、賞賛、苦情、憶測で埋め尽くされている。DeepSeek-R1は、OpenAI、Meta、その他の優れた推論モデルと比較されている。

CORAGの主要な貢献の概要 CORAG(Cost-Constrained Retrieval Optimization for Retrieval-Augmented Generation)は、既存のRAGアプローチの主要な課題に対処するために設計された革新的なRAG(Retrieval-Augmented Generation)システムである。以下のCORAG ...

知識蒸留は、事前に訓練された大きなモデル(すなわち「教師モデル」)から、より小さな「生徒モデル」へと学習を移行させることを目的とした機械学習技術である。蒸留技術は、知的対話、コンテンツ作成、その他の分野での軽量な生成モデルの開発に役立つ。 最近、ディスティレーション...

近年、大規模モデルの学習や推論に携わる多くの人々が、モデルのパラメータ数とモデルサイズの関係について議論している。例えば、有名なalpacaシリーズのLLaMAラージモデルには、LLaMA-7B、LLaMA-13B、LLaMA-33B、LLaMA-65Bというパラメータサイズの異なる4つのバージョンがある。 ここでは「...

元記事:https://arxiv.org/pdf/2412.15479 解釈:この記事自体はあまり革新的ではなく、応用も利かない。しかし、ずっとずっと昔に読んだ非常に有益な3つの記事を思い起こさせる。 前の3つの記事と合わせてこの記事を読むことで、より多くのインスピレーションが得られることを期待したい。お薦めの一冊:...

人工知能や機械学習の分野では、特にRAG(Retrieval Augmented Generation)システムやセマンティック検索などのアプリケーションを構築する際、膨大な量の非構造化データを効率的に処理・検索することが極めて重要になる。ベクターデータベースは、この課題に対処するための中核技術として登場した。ベクターデータベースは、高次元データを格納するためだけのものではない。

中国だけでなくアジアでも話題のソーシャルEコマースプラットフォーム「小紅秀」は、単なるショッピングアプリの域を超え、若者のライフスタイルの風見鶏となり、ブランドマーケティングの新たなポジションを確立して久しい。中国市場に参入したい、あるいは若い消費者にリーチしたいと考える海外のブランドや個人にとって、小紅樹を使いこなすことは...

思いがけず、AIはプログラミング分野に半端ない変革の空を起こしている。v0、bolt.newから、Agantを組み合わせた様々なプログラミングツールCursorやWindsurfまで、AIコーディングはアイデアMVPの巨大な可能性を秘めている。伝統的なAIアシスト・コーディングから、今日の直接的なプロジェクト生成の背後にあるものまで、結局は...。
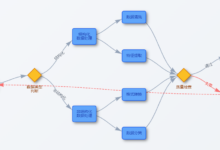
ワークフロー:簡単に言えば、「何かを成し遂げるための完全な手順」のこと。 目標に到達するために、誰が、どのような順序で、何をすべきかを示した「取扱説明書」のようなものだ。 インプット:ワークフローを開始する前に、...
この記事は「知的身体AIの理解と展開」シリーズの一部です:知的身体AIシリーズ1:Devinとエージェント・カーソルの比較 知的身体AIシリーズ2:考える人から実行する人へ-知的身体AIのパラダイム革命と技術アーキテクチャ知的身体AIと技術アーキテクチャ 知的身体AIシリーズ3:20ドルを50ドルに...

大規模言語モデル(LLM)アプリケーションを構築する際、メモリシステムは対話のコンテキスト管理、長期的な情報保存、意味理解を強化する重要な技術の一つである。効率的なメモリシステムは、モデルが長い対話の一貫性を維持し、重要な情報を抽出し、さらに過去の対話を検索する機能を持つことができます...

OpenAIの関数呼び出しV2の特徴 関数呼び出しV2の中核的な目標は、OpenAIのモデルに外界と相互作用する能力を与えることです。

基本概念 情報技術の分野では、検索とは、ユーザーの問い合わせや必要性に応じて、大規模なデータセット(通常は文書、ウェブページ、画像、音声、動画、その他の形式の情報)から関連する情報を効率的に探し出し、抽出するプロセスを指す。 その中心的な目的は、使用目的に関連する情報を見つけることである。
![Agent AI: 探索多模态交互的前沿世界[李飞飞-经典必读]-首席AI分享圈](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)
Agent AI: Surveying the Horizons of Multimodal Interaction Original published at https://ar5iv.labs.arxiv.org/html/2401.03568 Abstract マルチモーダルAIシステムは、我々の日常生活においてユビキタスになる可能性が高い。このようなシステムをよりインタラクティブなものにする一つの方法として ...

GraphReader:大規模な言語モデルのための長文テキスト処理を強化するグラフベースのインテリジェンス Graphic Expert:マインドマップを作るのが得意な家庭教師のように、長文テキストを明確な知識ネットワークに変換することで、AIが地図に沿って探索するように、答えに必要な各キーポイントを簡単に見つけることができ、効果的に...

CAG(キャッシュ・オーグメンテッド・ジェネレーション)は、RAG(リトリーバル・オーグメンテッド・ジェネレーション)よりも40倍高速です。CAGは、知識獲得に革命をもたらします:リアルタイムで外部データを取得する代わりに、すべての知識がモデル・コンテキストにあらかじめロードされます。CAGは知識獲得に革命をもたらします:外部データをリアルタイムで取得する代わりに、すべての知識がモデル・コンテキストに事前にロードされます。これは、巨大なライブラリを、必要なときにすぐに使えるツールキットに凝縮したようなものです...

ジュリア・ヴィージンガー、パトリック・マーロウ、ウラジミール・ヴスコヴィッチ 著 原文 https://www.kaggle.com/whitepaper-agents 目次 はじめに インテリジェント・ボディとは何か? モデル ツール オーケストレーションレイヤー インテリジェントボディとモデル 認知アーキテクチャ:インテリジェントボディの仕組み ツール ...