
ChatTTS:実際の人の話し声を模倣した音声生成モデル(ChatTTSワンクリックアクセラレーションパッケージ)
一般的な紹介 ChatTTSは対話シナリオ用に設計された生成音声モデルです。自然で表現力豊かな音声を生成し、多言語、複数話者をサポートし、対話型ダイアログに適しています。このモデルは、笑い、ポーズ、間投詞のような細かな韻律的特徴を予測し、制御することで、大規模なモデルを超えています...

一般的な紹介 ChatTTSは対話シナリオ用に設計された生成音声モデルです。自然で表現力豊かな音声を生成し、多言語、複数話者をサポートし、対話型ダイアログに適しています。このモデルは、笑い、ポーズ、間投詞のような細かな韻律的特徴を予測し、制御することで、大規模なモデルを超えています...

総合紹介 MoneyPrinterPlusは、AI技術を通じて、ワンクリックであらゆる種類の短い動画を生成・ミックスし、Jieyin、Shutterbugs、Xiaohongshu、Video Numberなどの複数の動画プラットフォームに自動的に公開することを目的としたオープンソースプロジェクトです。このツールは、chatTTS、fasterwhisper、G...などのローカルおよびクラウドベースの音声モデルをサポートしています。

ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。

包括的な紹介 TF-ID(Table/Figure IDentifier)は、学術論文から表や画像を抽出するためのオブジェクト検出モデル群である。このプロジェクトはYifei Huによって作成され、GitHubでオープンソース化されています。TF-IDモデルは、学術論文から表や画像を認識・抽出するために微調整されています...

一般的な紹介 Chatbot UIは、開発者がパーソナライズされたインテリジェントな会話インターフェースを作成できるように設計されたオープンソースプロジェクトです。このプロジェクトは、ユーザーにスムーズでスマートな対話体験を提供するために、既存のチャットボットシステムに簡単に統合できる一連のインターフェースコンポーネントと対話機能を提供します。
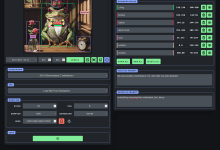
概論 GLIGEN GUIはComfyUIをベースとした直感的なグラフィカル・インターフェースであり、画像中のオブジェクトの位置を正確に指定することができる新しいテキストから画像へのモデルであるGLIGENモデルの使用を簡素化するように設計されている。GLIGEN GUIでは、ユーザはボックスを描いたり、テキストを入力したりすることでプロンプトが表示される...

包括的な紹介 Easy-Voice-Toolkitは、音声認識、音声トランスクリプション、音声変換、データセット作成、モデルトレーニングのための幅広い自動音声ツールを提供する、オープンソーススピーチプロジェクトに基づいた多目的ツールキットです。ユーザーは必要に応じて、これらのツールを選択的または連続的に使用することができます...

概要 FaceFusionは、画像からビデオ、画像から画像への交換プロセスを5つのプロフェッショナルモデルで最適化し、完璧な出力を保証する、顔交換とエンハンスメント機能を統合した最先端のクラウドプラットフォームです。さらに、3つの異なるモデルを使用して、7つのモデルでフェイシャル・エンハンスメントを実行します。

概論 Kotaemonは、RAG(Retrieval Augmented Generation)に基づいたQ&A機能をエンドユーザーや開発者に提供するために設計されたオープンソースのドキュメントQ&Aツールです。Cinnamonによって開発されたこのプロジェクトは、様々なLLM APIプロバイダー(OpenAI、AzureOpenAI、Cohereなど)をサポートし、またネイティブ...
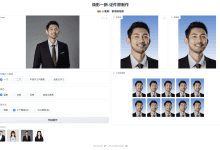
包括的な紹介 HivisionIDPhotosは、オープンソースの軽量AI文書写真制作ツールであり、インテリジェントにユーザーの写真のシーンとキーイングを識別することができ、様々な仕様に沿って標準的な文書の写真を生成します。このツールは、カスタム背景色とサイズをサポートしており、将来的には、美しさとインテリジェントな正装の変更機能を導入する予定です。このツールで...
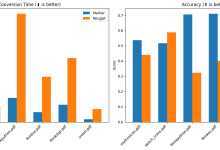
一般的な紹介 Markerは、PDFファイルをMarkdown形式に迅速かつ正確に変換するために設計されたディープラーニングベースの文書処理ツールです。幅広い種類のドキュメントをサポートし、特に書籍や科学論文の変換に最適化されています。Markerは、ヘッダーやフッターなどの冗長なコンテンツを削除し、表や...
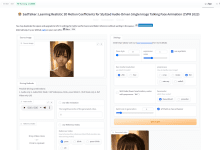
はじめに SadTalkerは、1枚の静止画と音声ファイルを組み合わせて、パーソナライズされたメッセージや教育コンテンツなど、幅広いシナリオに対応するリアルなトーキングヘッドビデオを作成するオープンソースツールです。ExpNetやPoseVAEなどの3Dモデリング技術の革命的な使用により、微妙なファセットを捉えることに優れています。

一般的な紹介 VideoReTalkingは、ユーザーが入力音声に基づいてリップシンクロナイズされた顔映像を生成し、異なる感情であっても高品質でリップシンクロナイズされた出力映像を生成できる革新的なシステムである。このシステムは、この目標を3つの連続したタスクに分解する。

一般的な紹介 MuseVはGitHubで公開されているプロジェクトで、長さ無制限で忠実度の高いアバター動画の生成を可能にすることを目的としています。拡散技術に基づいており、Image2Video、Text2Image2Video、Video2Videoなどの様々な機能を提供します。モデル構造、ユースケース、クイックスタート...

包括的な紹介 Unstructured-IOは、PDF、HTML、Word文書などの画像やテキスト文書の処理と前処理のためのオープンソースコンポーネントのセットを提供します。その主な目的は、特に大規模言語モデル(LLM)アプリケーションをサポートするために、データ処理ワークフローを簡素化し最適化することです。
一般的な紹介 magic-htmlは、HTMLから本文領域のコンテンツを抽出するプロセスを簡素化するために設計されたPythonライブラリです。複雑なHTML構造を扱う場合でも、単純なウェブページを扱う場合でも、このライブラリはユーザに便利で効率的なインターフェースを提供することを目的としています。マルチモーダル抽出、マルチレイアウト抽出、...

WebPilot 概要 Webpilotはフリーでオープンソースの "ウェブアシスタント "です。ページを切り替えたり、コピー&ペーストする代わりに、テキストを選択したり、コマンドを入力するだけで、ウェブパイロットはリアルタイムの情報とスマート...
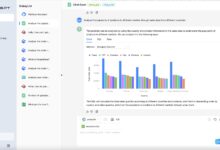
包括的な紹介 DB-GPTは、AWEL(Agentic Workflow Expression Language)とスマートボディ技術を用いて構築されたオープンソースのAIネイティブデータアプリケーション開発フレームワークです。このプロジェクトは、マルチモデル管理システム(SMMF)、...

DreamTalk総合紹介 DreamTalkは、清華大学、アリババグループ、華中科技大学が共同開発した拡散モデル駆動型表情トーキングヘッド生成フレームワークです。主に、ノイズ除去ネットワーク、スタイル認識リップエキスパート、スタイル予測器の3つの部分から構成され、...

包括的な紹介 InstantIDは、単一の参照ID画像を使用して、高い忠実度を確保しながら、パーソナライズされたスタイルやポーズを持つ画像を数秒で生成することに焦点を当てた先進技術です。この技術は、顔画像とランドマーク画像を統合することにより、拡散モデルに基づいたソリューションを使用します。




