Ollama OCR: Ollamaの視覚モデルを使った画像からのテキスト抽出
包括的な紹介 Ollama OCRは、Ollamaプラットフォームが提供する最先端の視覚言語モデルを使用して画像からテキストを抽出する、強力な光学式文字認識(OCR)ツールキットです。このプロジェクトは、Pythonパッケージとして利用できるほか、ユーザーフレンドリーなStreamlitウェブ・アプリケーション・インターフェースを提供しています。このツールキットは複数の...

包括的な紹介 Ollama OCRは、Ollamaプラットフォームが提供する最先端の視覚言語モデルを使用して画像からテキストを抽出する、強力な光学式文字認識(OCR)ツールキットです。このプロジェクトは、Pythonパッケージとして利用できるほか、ユーザーフレンドリーなStreamlitウェブ・アプリケーション・インターフェースを提供しています。このツールキットは複数の...
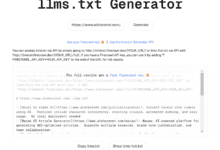
包括的な紹介 llmstxt-generatorは、大規模言語モデル(LLM)の学習と推論のための高品質なテキストデータセットを準備することに特化した、専門的なウェブコンテンツの抽出と統合ツールです。Mendable AIによって開発されたこのツールは、@firecrawl_devによって提供されたウェブクローリング技術とGPT-4-miniを使用しています。

ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。

包括的な紹介 Doc2Xは、強力な文書画像数式認識と変換ツールで、効率的でインテリジェントな文書処理ソリューションを提供することを約束します。学術研究論文、教科書、企業文書、財務報告書など、Doc2XはPDF内の表や数式を正確に識別し、1つのキーで変換することができます...

ExtractThinkerは、大規模言語モデル(LLM)を活用してドキュメントから構造化データを抽出・分類し、ORMのようなシームレスなドキュメント処理ワークフローを提供する、柔軟なドキュメントインテリジェンスツールです。Tesseract OCR、Azure Form Recog...など、複数のドキュメントローダーをサポートしています。

包括的な紹介 HtmlRAGは、RAG(Retrieval Augmented Generation)システムにおけるHTML文書の処理を改善することに焦点を当てた、革新的なオープンソースプロジェクトである。このプロジェクトは、RAGシステムにおけるHTMLフォーマットの使用が、プレーンテキストよりも効率的であるという新しいアプローチを提案する。このプロジェクトは、HTML文書の検索から検索結果の表示までの完全なデータ処理フローを包含している。
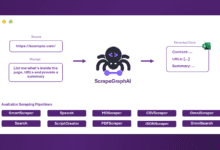
包括的な紹介 ScrapeGraphAIは、ラージ・ランゲージ・モデリング(LLM)とダイレクト・グラフ・ロジックを巧みに組み合わせ、ウェブサイトやローカル・ドキュメントのスクレイピング・パイプラインを作成する革新的なPythonウェブ・スクレイピング・ライブラリです。このツールのユニークさは、シンプルさとパワーの完璧なバランスにある。

総合紹介 Vision Parseは、最先端の視覚言語モデル(Vision Language Models)技術を巧みに組み合わせ、PDF文書を高品質なMarkdown形式のコンテンツにインテリジェントに変換する画期的な文書処理ツールです。このツールは、一流の視覚言語モデルを幅広くサポートしています。

概論 Outlinesはdottxt-aiによって開発されたオープンソースライブラリで、構造化テキスト生成を通して大規模言語モデル(LLM)のアプリケーションを強化します。このライブラリは、OpenAI、トランスフォーマー、llama.cppなど、様々なモデルの統合をサポートしています。

一般的な紹介 MarkItDownはMicrosoftによって開発されたPythonツールで、様々なファイルやオフィス文書をMarkdown形式に変換するように設計されています。このツールは、PDF、PowerPoint、Word、Excel、画像(EXIFメタデータとOCR)、音声(EXIFメタデータと言語...

包括的な紹介 Chunkrは、PDF、PPTX、DOCX、ExcelファイルをRAG(Retrieval Augmented Generation)やLLM(Large Language Modelling)で使用するのに適したデータに変換するためのセルフホストAPIです。このAPIはLumina AI Inc.によって開発され、ドキュメントの取り込みに高度なビジュアルモデルを使用しています。

概要 GitIngestは、GitHubのコードリポジトリをLarge Language Model (LLM)のヒントに適したテキストに変換するために設計されたオープンソースツールです。簡単な操作で、GitHubリポジトリの内容をLLMに適したテキストに抽出・整形することができます。このツールは、ワンクリックで解析...

一般的な紹介 E2M (Everything to Markdown)は、幅広いファイル形式をMarkdown形式に変換するために設計されたオープンソースのPythonライブラリです。このツールは、doc、docx、epub、html、htm、url、pdf、ppt、pptx、mp3、m4aを含む幅広いファイル形式をサポートしています。

包括的な紹介 Doclingは、PDF、DOCX、PPTX、XLSX、画像、HTML、AsciiDocおよびMarkdownを含む幅広い文書形式をサポートする、強力な文書解析およびエクスポートツールです。
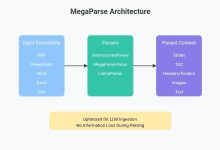
一般的な紹介 MegaParseは、大規模言語モデル(LLM)のデータ処理を最適化するために設計された、強力で多機能な文書解析ツールです。MegaParseは、テキスト、PDF、PowerPointプレゼンテーション、Word文書など、どのような文書を処理する場合でも、簡単に、そして確実に解析処理を行うことができます。
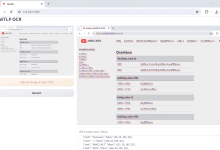
包括的な紹介 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)は、視覚的にガイドされた生成的なテキストレイアウトの事前学習モデルを通じて、ドキュメントインテリジェンス処理を強化することを目的としたオープンソースプロジェクトです。このプロジェクトはVeason-silverbul...によって開発されました。

概要 Trieveは、検索、レコメンデーション、RAG(Retrieval Augmented Generation)、分析のために設計された、Devflow, Inc.によって開発された包括的なインフラストラクチャです。このプラットフォームはAPI経由で提供され、セルフホスティングをサポートし、AWS、GCP、Kubernetes、Docker Composeなどの環境で利用可能です。

包括的な紹介 pdf2htmlEXは、PDFファイルをHTML形式に変換するために設計されたオープンソースのツールです。PDFファイルの内容を分析し、正確にその視覚効果を復元するためにHTML + CSSを使用することにより、ブラウザにPDF文書をWebページ上で直接見ることができます。このツールは、特に多くのPDFファイルを含む場合に適しています。

包括的な紹介 Maxunはオープンソースのコード不要のウェブデータ抽出プラットフォームで、ウェブデータを自動的にクロールしてAPIやスプレッドシートに変換するロボットを数分で訓練することができます。このプラットフォームは、ページングとスクロールをサポートし、ウェブサイトのレイアウトの変更に対応し、強力なデータクローリング機能を提供します。

概要 OmniParseは、あらゆる非構造化データを構造化された実用的なデータに変換するために設計された強力なデータ解析および最適化プラットフォームで、GenAI(Generative Artificial Intelligence)フレームワーク用に最適化されています。文書、表、画像、動画、音声ファイル、ウェブコンテンツのいずれを扱う場合でも、OmniParseは...