

随着大型语言模型技术的飞速发展和广泛应用,其潜在的安全风险日益成为业界关注的焦点。为了应对这些挑战,全球众多顶尖科技公司、标准化组织及研究机构纷纷构建并发布了各自的安全框架。本文将梳理并剖析其中九个具有代表性的大模型安全框架,旨在为相关领域的从业者提供一个清晰的参考。

图:大模型安全框架概览
Google 的 Secure AI Framework (SAIF) (2025.04 发布)
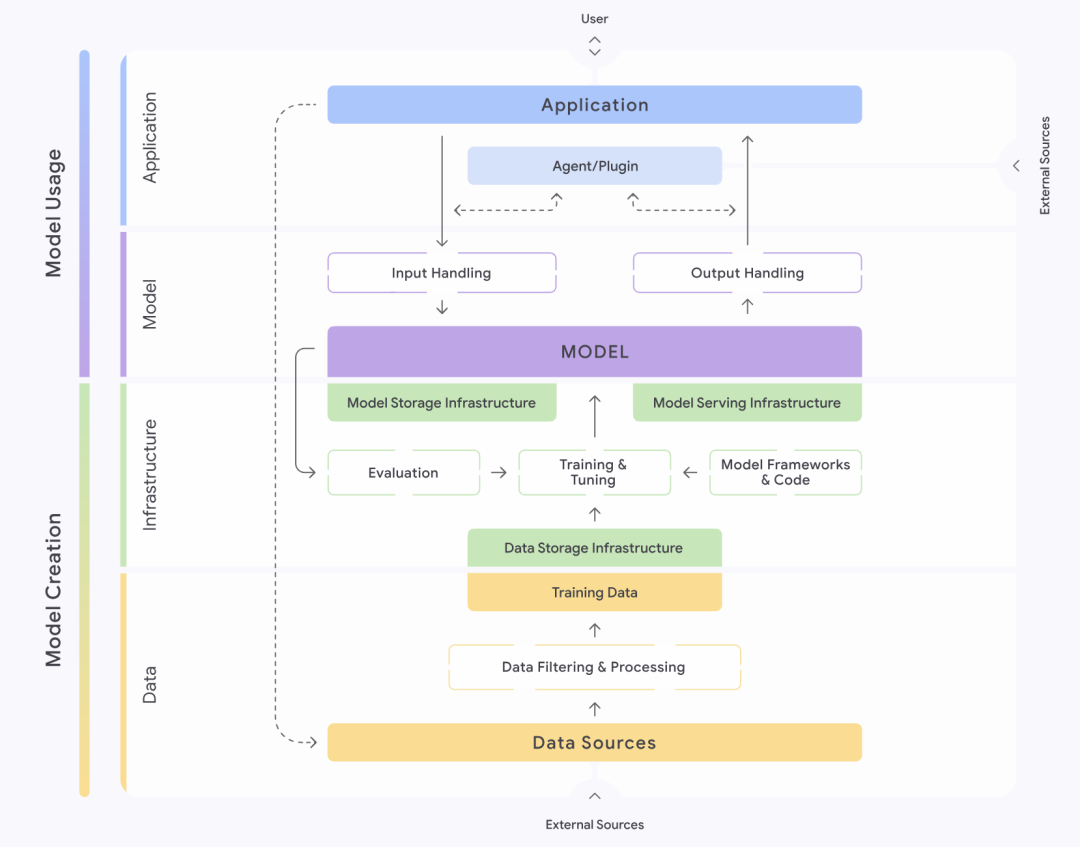
图:Google SAIF 框架结构
谷歌(Google)推出的 Secure AI Framework,简称 SAIF,提供了一个结构化的方法来理解和管理 AI 系统的安全。该框架将 AI 系统细致地划分为数据、基础设施、模型及应用四个层面。每一层面又进一步分解为不同的组件环节,例如数据层就包含了数据来源、数据过滤与处理、训练数据等关键部分。SAIF 强调,每个环节都潜藏着特定的风险隐患。
基于 AI 系统的完整生命周期,SAIF 识别并梳理了十五项主要风险,其中包括数据中毒、未经授权访问训练数据、模型源篡改、过度数据处理、模型泄漏、模型部署篡改、模型拒绝服务、模型逆向工程、不安全组件、提示词注入、模型扰乱、敏感数据泄漏、通过推断获取敏感数据、不安全的模型输出以及恶意行为。针对这十五项风险,SAIF 也相应地提出了十五项防控措施,构成了其核心的安全指导。
OWASP 的大模型应用 Top 10 安全威胁 (2025.03 发布)

图:OWASP 大模型应用 Top 10 安全威胁
开放全球应用程序安全项目(OWASP)作为网络安全领域的重要力量,也针对大模型应用发布了其标志性的 Top 10 安全威胁列表。OWASP 将大模型应用系统解构为几个关键的“信任域”,具体包括大模型服务本身、第三方功能插件、私有数据库以及外部训练数据等。该组织指出,无论是这些信任域之间的交互过程,还是信任域内部,都存在着诸多安全威胁。
OWASP 评选出的十大影响最为显著的安全威胁依次是:提示词注入、敏感信息泄露、供应链风险、数据与模型投毒、不当输出处理、过度授权、系统提示泄漏、向量与嵌入漏洞、信息误导以及无限资源消耗。针对每一项威胁,OWASP 都给出了相应的防控建议,为开发者和安全人员提供了实践指导。
OpenAI 的模型安全框架 (持续更新中)
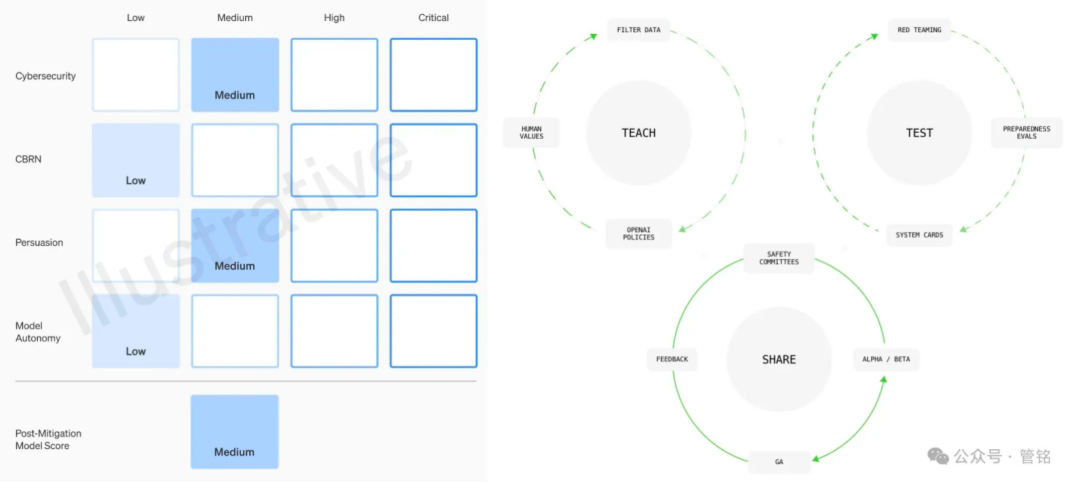
图:OpenAI 模型安全框架维度
作为大模型技术的领军者,OpenAI 对其模型的安全性给予了高度重视。其模型安全框架主要从四个维度展开:大规模杀伤性武器(CBRN)风险、网络攻击能力、说服力(即模型影响人类观点和行为的能力)以及模型自主性。OpenAI 根据潜在危害程度,将这些风险划分为低、中、高、严重四个等级。在每次模型发布之前,都必须依据此框架提交详细的安全评估结果,即所谓的“系统卡”(System Card)。
此外,OpenAI 还提出了一套包含价值观对齐、对抗评估和管控迭代的治理框架。在价值观对齐阶段,OpenAI 致力于制定一套符合人类普世价值观的模型行为规范,并以此指导模型训练各个阶段的数据清洗工作。在对抗评估阶段,OpenAI 会构建专业的测试用例,对采取防护措施前后的模型进行全面测试,最终产出系统卡。而在管控迭代阶段,OpenAI 会对已上线部署的模型采取分批上线策略,并持续添加和优化防护措施。
网安标委的人工智能安全治理框架 (2024.09 发布)
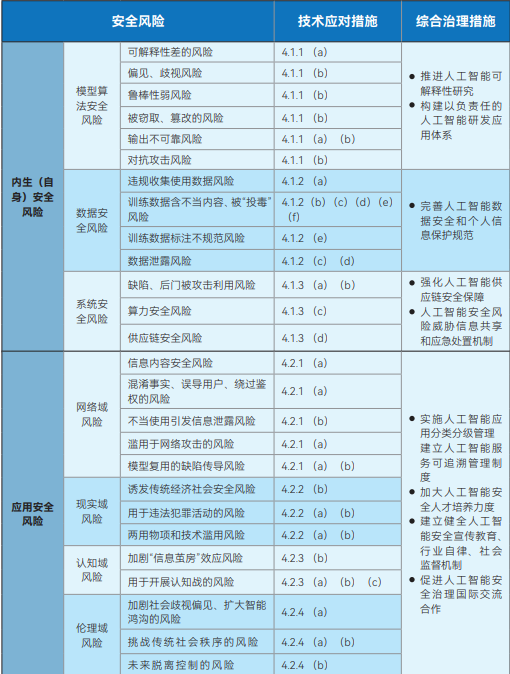
图:网安标委人工智能安全治理框架
全国网络安全标准化技术委员会(简称网安标委)发布的人工智能安全治理框架,旨在为人工智能的安全发展提供宏观指导。该框架将人工智能安全风险划分为两大类:内生(自身)安全风险和应用安全风险。内生安全风险指的是模型自身固有的风险,主要包括模型算法安全风险、数据安全风险和系统安全风险。应用安全风险则指模型在应用过程中可能面临的风险,并进一步细分为网络域、现实域、认知域和伦理域四个方面。
针对这些识别出的风险,该框架明确指出,模型算法的研发者、服务提供者、系统使用者等相关方,需要从训练数据、算力设施、模型算法、产品服务以及应用场景等多个方面积极采取技术措施进行防范。同时,框架倡导建立和完善一个由技术研发机构、服务提供者、用户、政府部门、行业协会和社会组织等多方共同参与的人工智能安全风险综合治理制度规范体系。
网安标委的人工智能安全标准体系V1.0 (2025.01 发布)
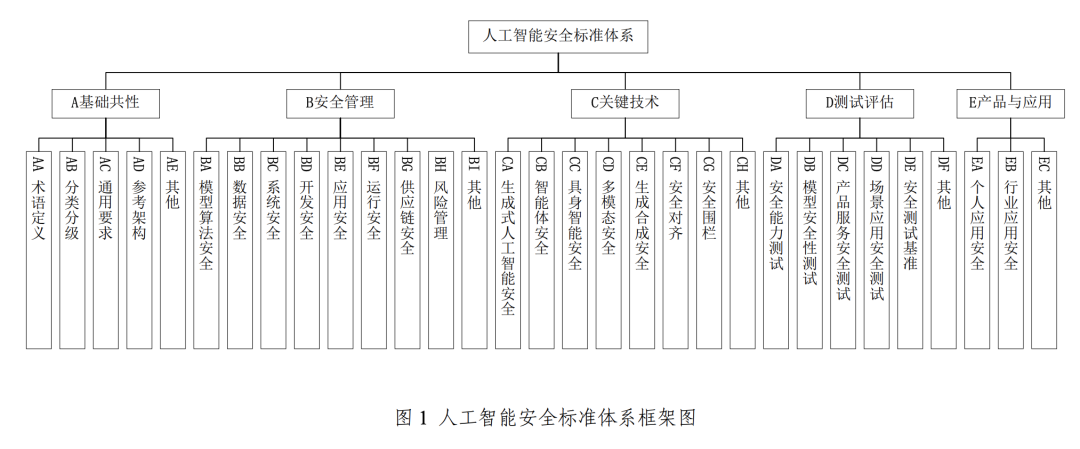
图:网安标委人工智能安全标准体系V1.0
为支撑并落实前述的《人工智能安全治理框架》,网安标委进一步推出了人工智能安全标准体系 V1.0。该体系系统梳理了能够帮助防范和化解相关人工智能安全风险的重点标准,并注重与现有的网络安全国家标准体系进行有效衔接。
此标准体系主要由五个核心部分构成:基础共性、安全管理、关键技术、测试评估以及产品与应用。其中,关键的安全管理部分涵盖了模型算法安全、数据安全、系统安全、开发安全、应用安全、运行安全和供应链安全。而关键技术部分则聚焦于生成式人工智能安全、智能体安全、具身智能安全(指拥有物理实体的 AI,如机器人,其安全涉及与物理世界的交互)、多模态安全、生成合成安全、安全对齐以及安全围栏等前沿领域。
清华大学、中关村实验室与蚂蚁集团联合发布的大模型安全实践2024 (2024.11 发布)
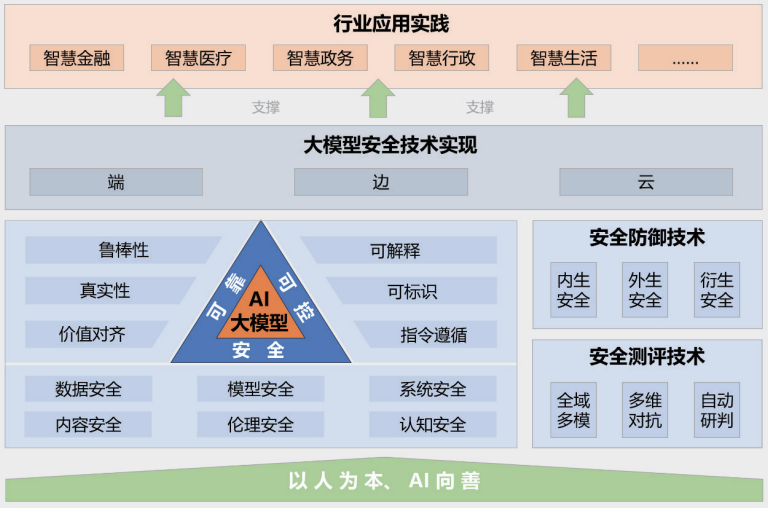
图:大模型安全实践2024框架
由清华大学、中关村实验室及蚂蚁集团联合发布的《大模型安全实践2024》报告,从产学研结合的视角提供了对大模型安全的洞察。该报告提出的大模型安全框架包含五个主要部分:“以人为本、AI向善”的建设指导思想;安全可靠可控的大模型安全技术体系;安全测评和防御技术;端、边、云协同的安全技术实现;以及在多个行业的应用实践案例。
报告详细指出了大模型当前面临的诸多风险挑战,例如数据泄漏、数据窃取、数据投毒、对抗攻击、指令攻击(通过精心设计的指令诱导模型产生非预期行为)、模型窃取攻击、硬件安全漏洞、软件安全漏洞、框架自身安全问题、外部工具引入的安全风险、毒性内容生成、偏见内容传播、虚假信息生成、意识形态风险、电信诈骗与身份盗窃、知识产权与版权侵犯、教育行业的诚信危机以及由偏见诱发的公平性问题等。针对这些复杂的风险,报告也同步提出了相应的防御技术。
阿里云与信通院联合发布的大模型安全研究报告 (2024.09 发布)
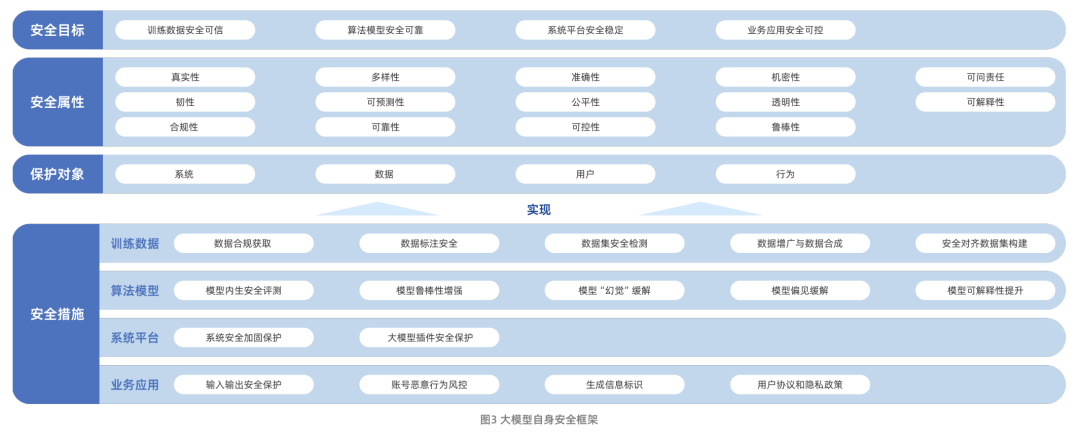
图:阿里云&信通院大模型安全研究报告框架
阿里云联合中国信息通信研究院(信通院)共同发布的《大模型安全研究报告》,系统阐述了大模型技术的演进路径及其当前所面临的安全挑战。这些挑战主要包括数据安全风险、算法模型安全风险、系统平台安全风险以及业务应用安全风险。值得注意的是,该报告将大模型安全的研究范围从模型自身的安全性,进一步扩展到了如何利用大模型技术赋能和提升传统网络安全防护能力。
在模型自身安全方面,报告构建了一个包含安全目标、安全属性、保护对象和安全措施四个维度的框架。其中,安全措施是围绕训练数据、模型算法、系统平台和业务应用这四个核心方面展开的,体现了全方位的防护思路。
腾讯研究院的大模型安全与伦理研究2024 (2024.01 发布)

图:腾讯研究院大模型安全与伦理研究关注点
腾讯研究院发布的《大模型安全与伦理研究2024》报告,深入分析了大模型技术的发展趋势,以及这些趋势为安全行业带来的机遇与挑战。报告列举了十五项主要风险,包括数据泄漏、数据投毒、模型篡改、供应链投毒、硬件漏洞、组件漏洞以及平台漏洞等。同时,报告分享了四项大模型安全最佳实践:Prompt 安全测评、大模型蓝军攻防演练、大模型源码安全防护实践以及大模型基础设施漏洞安全防护方案。
该报告还特别强调了大模型价值观对齐的进展和未来趋势。报告指出,如何确保大模型的能力和行为与人类的价值观、真实意图以及伦理原则相一致,从而保障人类与人工智能协作过程中的安全与信任,已经成为大模型治理的核心议题。
360 的大模型安全解决方案 (持续更新中)
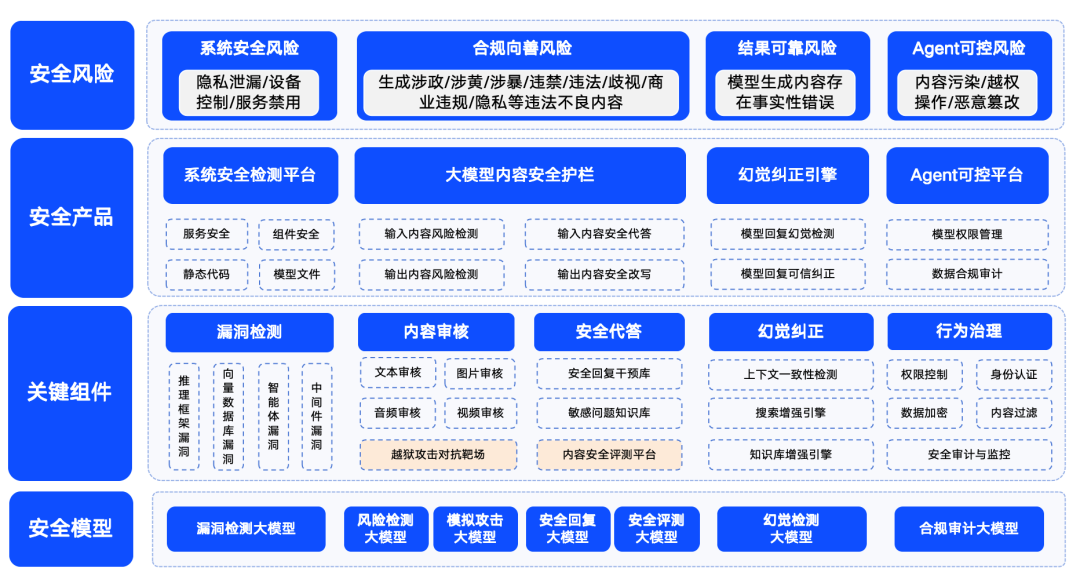
图:360 大模型安全解决方案示意
奇虎360 公司也积极布局大模型安全领域,并提出了其安全解决方案。360 将大模型安全风险归纳为四大类别:系统安全风险、内容安全风险、可信安全风险以及可控安全风险。其中,系统安全主要指大模型生态链中各类软件的安全性;内容安全关注输入输出内容的合规性风险;可信安全则聚焦于解决模型的“幻觉”问题(即模型生成看似合理但不真实的信息);可控安全则处理更为复杂的 Agent 流程安全问题。
为了确保大模型能够安全、向善、可信、可控地在各行业落地应用,360 基于自身在大模型领域的能力积累,打造了一系列大模型安全产品。这些产品包括主要针对 LLM 生态链漏洞检测的“360智鉴”,专注于大模型内容安全的“360智盾”,以及保障可信安全的“360智搜”。通过这些产品的组合,360 较早地形成了一套相对成熟的大模型安全解决方案。













