

Com o rápido desenvolvimento e a ampla aplicação de tecnologias de modelagem de linguagem em larga escala, seus possíveis riscos de segurança estão se tornando cada vez mais o foco da atenção do setor. Para enfrentar esses desafios, muitas das principais empresas de tecnologia, organizações de padronização e institutos de pesquisa do mundo todo criaram e lançaram suas próprias estruturas de segurança. Neste documento, classificaremos e analisaremos nove estruturas de segurança de grandes modelos representativos, com o objetivo de fornecer uma referência clara para os profissionais de áreas relacionadas.

Figura: Visão geral da estrutura de segurança do Big Model
Estrutura de IA segura (SAIF) do Google (versão 2025.04)
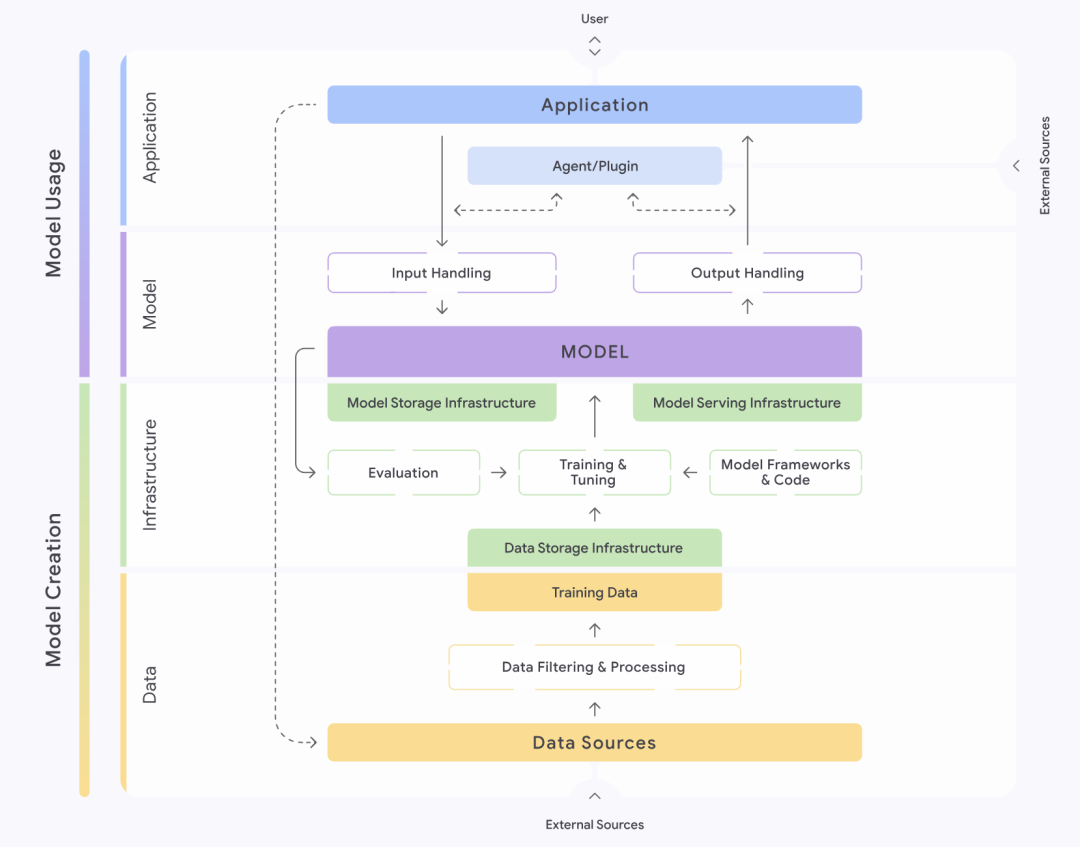
Figura: Estrutura da estrutura do Google SAIF
A Secure AI Framework, ou SAIF, introduzida pelo Google (Google), oferece uma abordagem estruturada para entender e gerenciar a segurança dos sistemas de IA. A estrutura divide meticulosamente os sistemas de IA em quatro camadas: dados, infraestrutura, modelo e aplicativo. Cada camada é subdividida em diferentes componentes, como a camada de dados, que contém partes importantes, como fontes de dados, filtragem e processamento de dados, dados de treinamento etc. A SAIF enfatiza que cada uma dessas partes abriga riscos e perigos específicos.
Com base no ciclo de vida completo de um sistema de IA, o SAIF identifica e classifica quinze riscos principais, incluindo envenenamento de dados, acesso não autorizado a dados de treinamento, adulteração da fonte do modelo, processamento excessivo de dados, vazamento do modelo, adulteração da implantação do modelo, negação de serviço do modelo, engenharia reversa do modelo, componentes inseguros, injeção de palavras-chave, embaralhamento do modelo, vazamento de dados confidenciais, acesso a dados confidenciais por meio de extrapolação, saída insegura do modelo e comportamento mal-intencionado. saída do modelo e comportamento malicioso. Em resposta a esses quinze riscos, o SAIF também propõe quinze medidas preventivas e de controle, que constituem sua principal orientação de segurança.
As 10 principais ameaças de segurança da OWASP para aplicativos de grande porte (lançado em 2025.03)

Figura: As 10 principais ameaças à segurança dos aplicativos OWASP Big Model
O Open World Application Security Project (OWASP), uma das principais forças da segurança cibernética, também divulgou sua exclusiva lista das 10 principais ameaças à segurança para aplicativos de modelos grandes. O OWASP desconstrói os aplicativos de modelos grandes em vários "domínios de confiança" importantes, incluindo o próprio serviço de modelo grande, funcionalidade de terceiros plug-ins, bancos de dados privados e dados de treinamento externos. A organização identifica uma série de ameaças à segurança, tanto nas interações entre esses domínios de confiança quanto dentro deles.
As 10 principais ameaças de segurança mais significativas da OWASP são, em ordem de impacto: injeção de prompt, divulgação de informações confidenciais, riscos à cadeia de suprimentos, envenenamento de dados e modelos, processamento inadequado de saída, autorização excessiva, vazamento de prompt do sistema, vulnerabilidades de vetor e incorporação, informações enganosas e consumo ilimitado de recursos. Para cada uma dessas ameaças, a OWASP oferece recomendações para prevenção e controle, fornecendo orientação prática para desenvolvedores e pessoal de segurança.
Estrutura de segurança do modelo da OpenAI (continuamente atualizada)
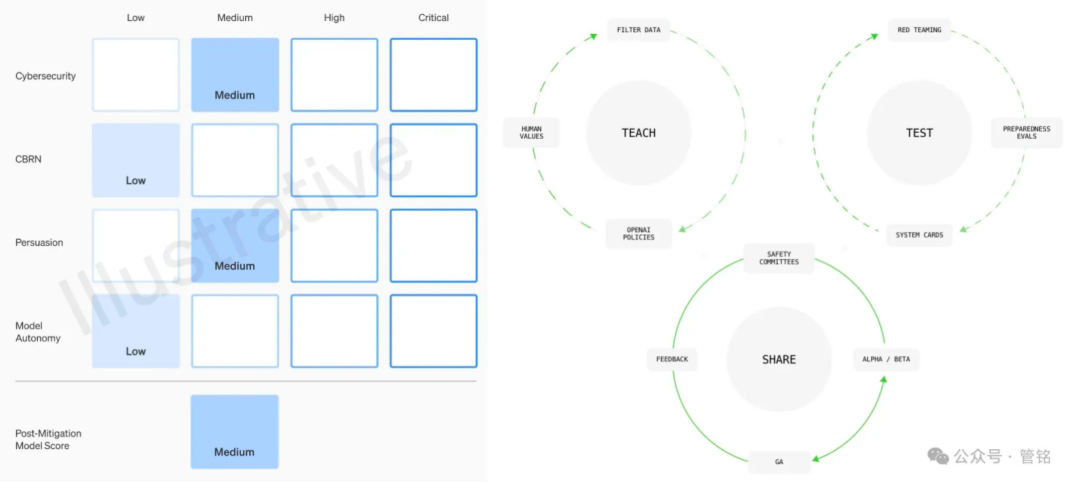
Figura: Dimensões da estrutura de segurança do modelo OpenAI
Como líder em tecnologia de Big Model, a OpenAI dá alta prioridade à segurança de seus modelos. Sua estrutura de segurança de modelos é baseada em quatro dimensões: risco de armas de destruição em massa (CBRN), capacidade de ataque cibernético, poder de persuasão (a capacidade dos modelos de influenciar opiniões e comportamentos humanos) e autonomia de modelos, que são classificados como baixo, médio, alto ou grave de acordo com o nível de dano potencial. Antes do lançamento de cada modelo, uma avaliação de segurança detalhada, conhecida como Cartão do Sistema, deve ser enviada com base nessa estrutura.
Além disso, a OpenAI propõe uma estrutura de governança que inclui alinhamento de valores, avaliação contraditória e iteração de controle. Na fase de alinhamento de valores, a OpenAI se compromete a formular um conjunto de comportamentos do modelo que sejam consistentes com os valores humanos universais e a orientar o trabalho de limpeza de dados em todas as fases do treinamento do modelo. Na fase de avaliação adversarial, a OpenAI criará casos de teste profissionais para testar completamente o modelo antes e depois de tomar medidas de proteção e, finalmente, produzir cartões de sistema. Na fase de iteração de controle, a OpenAI adotará uma estratégia de lançamento em lote para modelos que já foram implantados e continuará a adicionar e otimizar medidas de proteção.
Estrutura de governança de segurança de IA para o Comitê de Padrões de Segurança Cibernética (publicado em 2024.09)
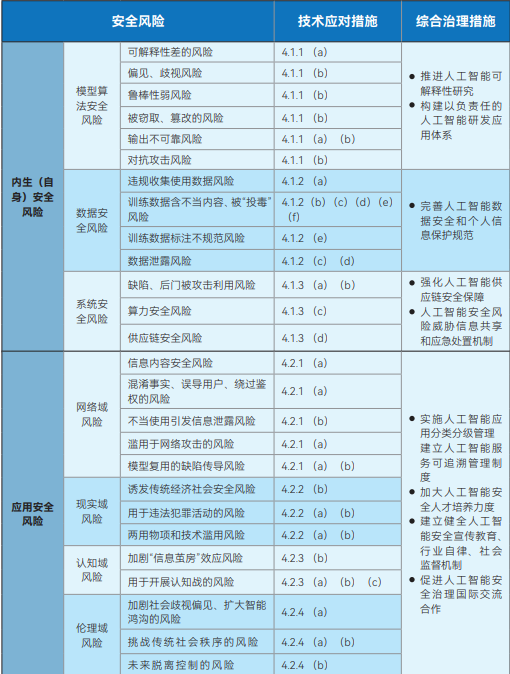
Figura: Estrutura de governança de segurança de IA do Net Security Standard Committee
A Estrutura de Governança de Segurança de Inteligência Artificial lançada pelo Comitê Técnico Nacional de Padronização de Segurança Cibernética (NCSSTC) tem como objetivo fornecer orientação macro para o desenvolvimento seguro da IA. A estrutura divide os riscos de segurança da IA em duas categorias principais: riscos de segurança endógenos (próprios) e riscos de segurança de aplicativos. Os riscos de segurança endógenos referem-se aos riscos inerentes ao próprio modelo, que incluem principalmente riscos de segurança do algoritmo do modelo, riscos de segurança dos dados e riscos de segurança do sistema. O risco de segurança do aplicativo, por outro lado, refere-se aos riscos que o modelo pode enfrentar no processo de aplicação e é subdividido em quatro aspectos: domínio da rede, domínio da realidade, domínio cognitivo e domínio ético.
Em resposta a esses riscos identificados, a estrutura aponta claramente que os desenvolvedores de modelos e algoritmos, provedores de serviços, usuários do sistema e outras partes relevantes precisam tomar ativamente medidas técnicas para evitá-los em vários aspectos, como dados de treinamento, instalações aritméticas, modelos e algoritmos, produtos e serviços, bem como cenários de aplicação. Ao mesmo tempo, a estrutura defende o estabelecimento e o aprimoramento de um sistema de governança abrangente para riscos de segurança de IA que envolva instituições de pesquisa e desenvolvimento de tecnologia, provedores de serviços, usuários, departamentos governamentais, associações do setor e organizações sociais.
Sistema padrão de segurança de inteligência artificial do Comitê de Padrões de Segurança Cibernética V1.0 (lançado em 2025.01)
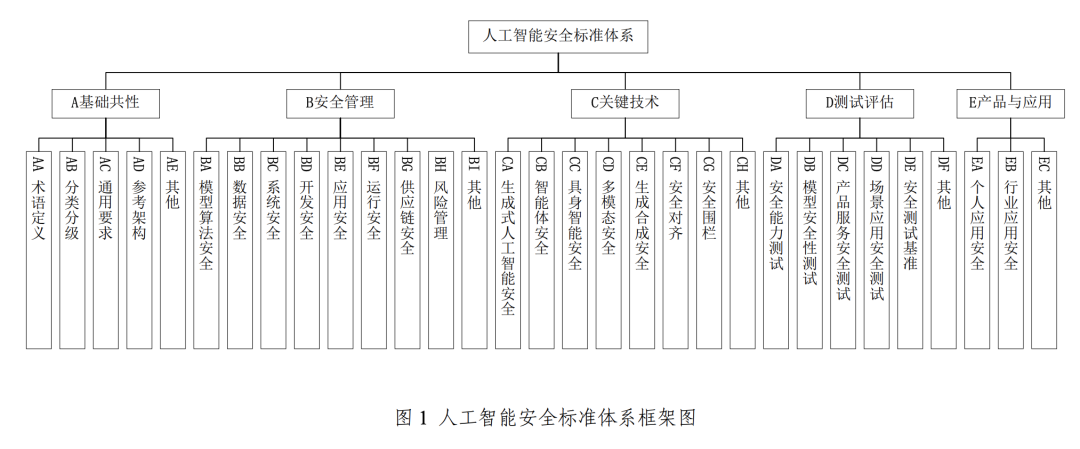
Figura: Sistema padrão de segurança de inteligência artificial do Comitê de Padrões de Segurança da Rede V1.0
Para apoiar e implementar a Estrutura de Governança de Segurança de Inteligência Artificial mencionada acima, o CNSC lançou ainda o Sistema Padrão de Segurança de Inteligência Artificial V1.0, que compila sistematicamente os principais padrões que podem ajudar a prevenir e resolver riscos relevantes de segurança de IA e se concentra na interface eficaz com o sistema padrão nacional existente para segurança cibernética.
Esse sistema de padrões é composto principalmente de cinco partes principais: uniformidade básica, gerenciamento de segurança, tecnologia-chave, testes e avaliação, e produtos e aplicativos. Entre elas, a parte de gerenciamento da segurança principal abrange a segurança do algoritmo do modelo, a segurança dos dados, a segurança do sistema, a segurança do desenvolvimento, a segurança do aplicativo, a segurança da operação e a segurança da cadeia de suprimentos. A seção de tecnologia-chave, por outro lado, concentra-se em áreas de ponta, como segurança de IA generativa, segurança de corpos inteligentes, segurança de inteligência incorporada (referente à IA com entidades físicas, como robôs, cuja segurança envolve interações com o mundo físico), segurança multimodal, segurança de síntese generativa, alinhamento de segurança e cercas de segurança.
Big Model Security Practices 2024 pela Universidade de Tsinghua, Zhongguancun Lab e Ant Group (lançado em 2024.11)
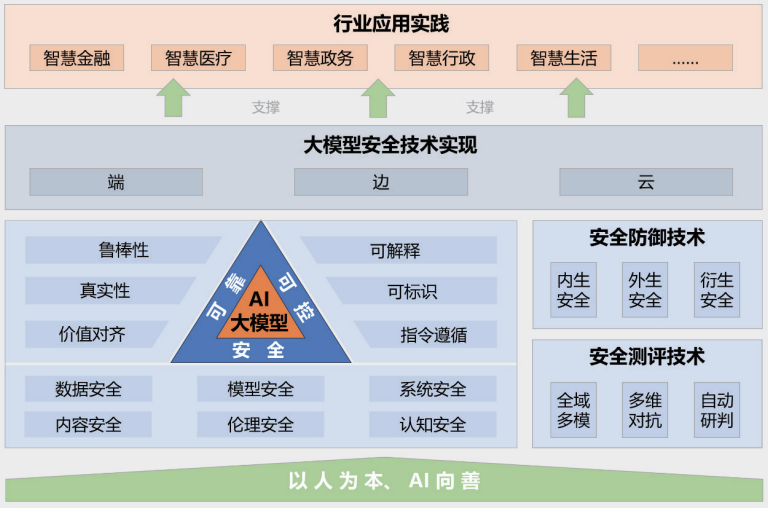
Figura: Estrutura das práticas de segurança do Big Model 2024
O relatório "Big Model Security Practice 2024", lançado em conjunto pela Universidade de Tsinghua, pelo Zhongguancun Lab e pelo Ant Group, fornece insights sobre a segurança de grandes modelos a partir da perspectiva de combinar o setor, a academia e a pesquisa. A estrutura de segurança de modelo grande proposta no relatório contém cinco partes principais: o princípio orientador de "orientado para as pessoas, IA para o bem"; um sistema de tecnologia de segurança de modelo grande seguro, confiável e controlável; tecnologias de medição e defesa de segurança; implementações de tecnologia de segurança colaborativa de ponta a ponta, de ponta a ponta e em nuvem; e casos de prática de aplicação em vários setores.
O relatório aponta em detalhes os muitos riscos e desafios que os grandes modelos estão enfrentando atualmente, como vazamento de dados, roubo de dados, envenenamento de dados, ataques adversários, ataques de comando (induzindo comportamentos não intencionais em modelos por meio de comandos bem projetados), ataques de roubo de modelos, vulnerabilidades de segurança de hardware, vulnerabilidades de segurança de software, problemas de segurança na própria estrutura, riscos de segurança introduzidos por ferramentas externas, geração de conteúdo tóxico, disseminação de conteúdo tendencioso, geração de informações falsas, riscos ideológicos, fraude de telecomunicações e roubo de identidade, propriedade intelectual e violação de direitos autorais, crise de integridade no setor de educação e problemas de justiça induzidos por preconceitos. geração de informações falsas, riscos ideológicos, fraude em telecomunicações e roubo de identidade, propriedade intelectual e violação de direitos autorais, crise de integridade no setor educacional e problemas de justiça induzidos por preconceitos. O relatório também propõe técnicas de defesa correspondentes para lidar com esses riscos complexos.
Relatório de pesquisa sobre segurança de grandes modelos da Aliyun e ICTA (publicado em 2024.09)
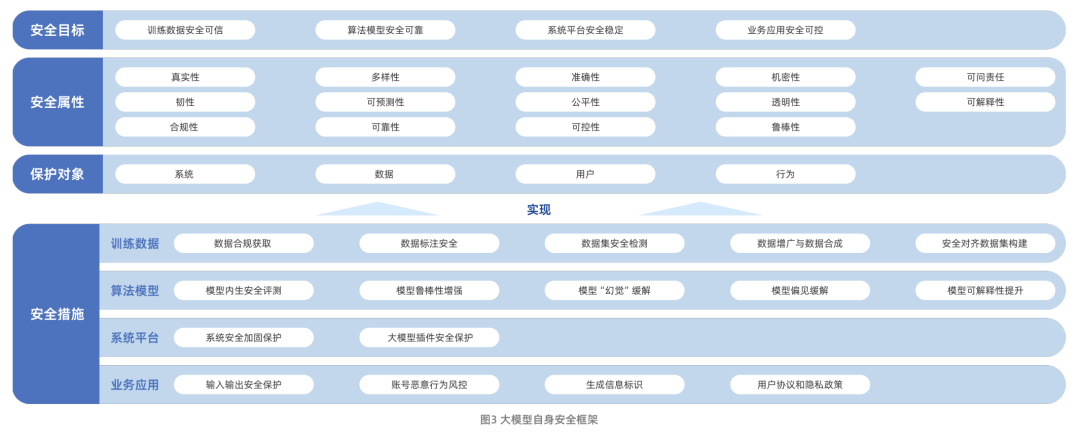
Figura: Estrutura do relatório de pesquisa sobre segurança de grandes modelos da Aliyun e da ICTA
O Relatório de Pesquisa sobre Segurança de Grandes Modelos, lançado em conjunto pela Aliyun e pela Academia Chinesa de Tecnologia da Informação e Comunicação (CAICT), descreve sistematicamente o caminho da evolução da tecnologia de grandes modelos e os desafios de segurança que ela enfrenta atualmente. Esses desafios incluem principalmente riscos à segurança de dados, riscos à segurança de modelos algorítmicos, riscos à segurança da plataforma do sistema e riscos à segurança de aplicativos comerciais. Vale ressaltar que o relatório amplia ainda mais o escopo de pesquisa da segurança de big models, desde a segurança do modelo em si até como usar a tecnologia de big models para capacitar e aprimorar os recursos tradicionais de proteção de segurança de rede.
Em termos da própria segurança do modelo, o relatório constrói uma estrutura com quatro dimensões: metas de segurança, atributos de segurança, objetos de proteção e medidas de segurança. Entre elas, as medidas de segurança estão centradas nos quatro aspectos principais de dados de treinamento, algoritmos de modelo, plataformas de sistema e aplicativos de negócios, refletindo uma ideia de proteção completa.
Estudo de Ética e Segurança do Grande Modelo do Instituto de Pesquisa Tencent 2024 (lançado em 2024.01)

Figura: Preocupações com a pesquisa de segurança e ética do Big Model do Tencent Research Institute
O relatório "Big Model Security and Ethics Research 2024", publicado pelo Tencent Research Institute, fornece uma análise aprofundada das tendências da tecnologia de modelos grandes e das oportunidades e desafios que essas tendências apresentam para o setor de segurança. O relatório lista quinze riscos principais, incluindo vazamento de dados, envenenamento de dados, adulteração de modelos, envenenamento da cadeia de suprimentos, vulnerabilidade de hardware, vulnerabilidade de componentes e vulnerabilidade de plataforma. Enquanto isso, o relatório compartilha quatro práticas recomendadas de segurança de modelos grandes: avaliação imediata da segurança, exercício de ataque e defesa do exército azul de modelos grandes, prática de proteção de segurança de código-fonte de modelos grandes e esquema de proteção de segurança de vulnerabilidade de infraestrutura de modelos grandes.
O relatório também destaca o progresso e as tendências futuras no alinhamento de valores de grandes modelos. O relatório observa que a forma de garantir que os recursos e comportamentos dos grandes modelos estejam alinhados com os valores humanos, as verdadeiras intenções e os princípios éticos, de modo a proteger a segurança e a confiança no processo de colaboração entre seres humanos e IA, tornou-se um tópico central da governança de grandes modelos.
Solução de segurança de modelo grande da 360 (continuamente atualizada)
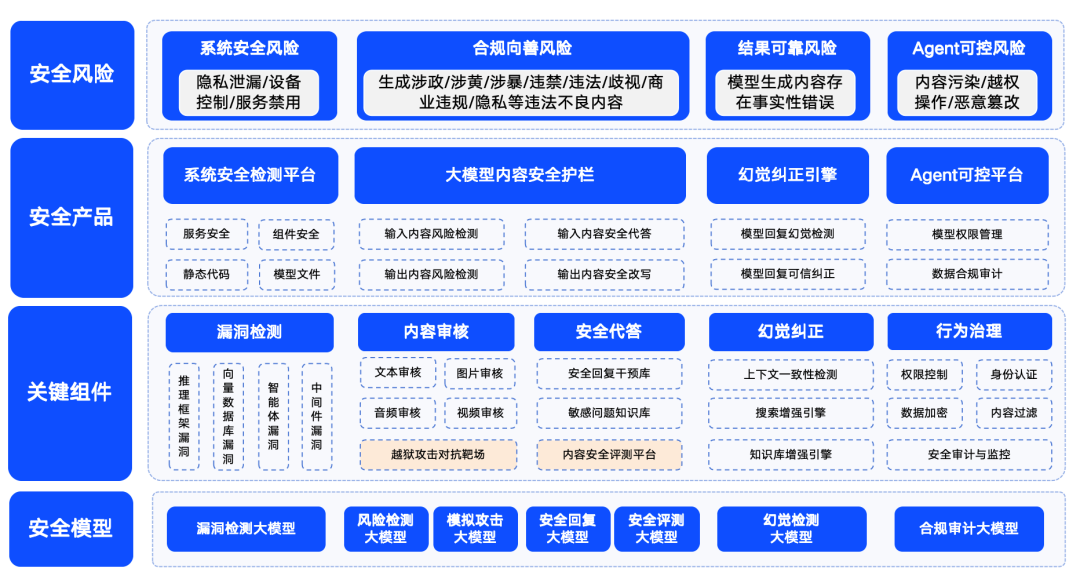
Figura: Esquema da solução de segurança 360 Big Model
A Qihoo 360 também estabeleceu ativamente o campo de segurança de modelos grandes e apresentou suas soluções de segurança. A 360 resume os riscos de segurança de modelos grandes em quatro categorias: riscos de segurança do sistema, riscos de segurança de conteúdo, riscos de segurança confiáveis e riscos de segurança controláveis. Entre eles, a segurança do sistema refere-se principalmente à segurança de vários tipos de software no ecossistema de grandes modelos; a segurança do conteúdo concentra-se no risco de conformidade do conteúdo de entrada e saída; a segurança confiável concentra-se na solução do problema de "ilusão" do modelo (ou seja, o modelo gera informações que parecem ser razoáveis, mas não são reais); e a segurança controlável lida com o problema mais complexo de segurança do processo do agente. A segurança controlada aborda o problema mais complexo da segurança do processo do agente.
Para garantir que os modelos grandes possam ser seguros, bons, confiáveis e controláveis para aplicação em vários setores, a 360 criou uma série de produtos de segurança para modelos grandes com base em seu próprio acúmulo de recursos no campo de modelos grandes. Esses produtos incluem o "360 Smart Forensics", que tem como objetivo principal detectar vulnerabilidades no ecossistema LLM, o "360 Smart Shield", que se concentra na segurança do conteúdo de modelos grandes, e o "360 Smart Search", que garante segurança confiável. 360SmartSearch". Com a combinação desses produtos, a 360 formou um conjunto de soluções de segurança relativamente maduras para modelos grandes em um estágio inicial.













