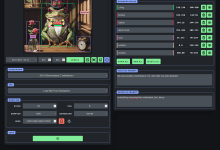
Introdução geral O ChatTTS é um modelo de fala generativo projetado para cenários de diálogo. Ele gera fala natural e expressiva, suporta vários idiomas e vários falantes e é adequado para diálogos interativos. O modelo vai além do grande, prevendo e controlando recursos prosódicos de granulação fina, como risos, pausas e interjeições...
Introdução abrangente O MoneyPrinterPlus é um projeto de código aberto que visa gerar e misturar todos os tipos de vídeos curtos com um clique por meio da tecnologia de IA e publicá-los automaticamente em várias plataformas de vídeo, como Jieyin, Shutterbugs, Xiaohongshu e Video Number. A ferramenta oferece suporte a modelos de voz locais e baseados em nuvem, incluindo chatTTS, fasterwhisper, G...
Habilite o modo de programação inteligente Builder, uso ilimitado do DeepSeek-R1 e DeepSeek-V3, experiência mais suave do que a versão internacional. Basta digitar os comandos chineses, sem conhecimento de programação, para escrever seus próprios aplicativos.
Introdução abrangente O TF-ID (Table/Figure IDentifier) é uma família de modelos de detecção de objetos dedicada à extração de tabelas e imagens de artigos acadêmicos. O projeto foi criado por Yifei Hu e tem código aberto no GitHub. Os modelos TF-ID são ajustados para reconhecer e extrair tabelas e imagens de artigos acadêmicos...
Introdução geral O Chatbot UI é um projeto de código aberto criado para ajudar os desenvolvedores a criar interfaces de conversação personalizadas e inteligentes. O projeto fornece uma série de componentes de interface e recursos interativos que podem ser facilmente integrados ao sistema de Chatbot existente para oferecer aos usuários uma experiência de diálogo mais suave e inteligente.
Introdução geral O GLIGEN GUI é uma interface gráfica intuitiva baseada no ComfyUI, projetada para simplificar o uso do modelo GLIGEN, um novo modelo de texto para imagem que permite a especificação precisa da posição dos objetos em uma imagem. Com o GLIGEN GUI, o usuário é solicitado a desenhar caixas e inserir texto...
Introdução abrangente O Easy-Voice-Toolkit é um kit de ferramentas multifuncional baseado no Open Source Speech Project que oferece uma ampla variedade de ferramentas de áudio automatizadas para reconhecimento de fala, transcrição de fala, conversão de fala, criação de conjuntos de dados e treinamento de modelos. Os usuários podem usar essas ferramentas de forma seletiva ou sequencial, conforme necessário...
Introdução geral O FaceFusion é uma plataforma de nuvem de última geração com recursos integrados de troca e aprimoramento facial que otimiza o processo de troca de imagem para vídeo e imagem para imagem com 5 modelos profissionais para garantir um resultado impecável. Além disso, ele executa o aprimoramento facial com 7 modelos, usando 3 modelos diferentes para...
Introdução geral O Kotaemon é uma ferramenta de perguntas e respostas de documentos de código aberto projetada para fornecer aos usuários finais e desenvolvedores recursos de perguntas e respostas com base no Retrieval Augmented Generation (RAG). Desenvolvido pela Cinnamon, o projeto oferece suporte a vários provedores de API LLM (por exemplo, OpenAI, AzureOpenAI, Cohere etc.), bem como a...
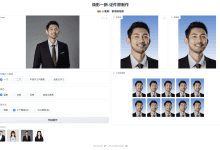
Introdução abrangente O HivisionIDPhotos é uma ferramenta de produção de fotos de documentos com IA leve e de código aberto, capaz de identificar de forma inteligente a cena da foto do usuário e a codificação, para gerar uma foto de documento padrão de acordo com uma variedade de especificações. A ferramenta suporta cor e tamanho de fundo personalizados e, no futuro, também introduzirá a função de beleza e mudança inteligente de trajes formais. Com...
Introdução geral O Marker é uma ferramenta de processamento de documentos baseada em aprendizagem profunda, projetada para converter arquivos PDF para o formato Markdown com rapidez e precisão. Ele oferece suporte a uma ampla variedade de tipos de documentos e é especialmente otimizado para a conversão de livros e artigos científicos. O Marker é capaz de remover conteúdo redundante, como cabeçalhos e rodapés, formatar tabelas e...
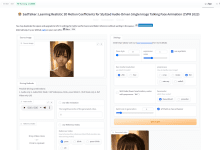
Introdução geral O SadTalker é uma ferramenta de código aberto que combina fotos de retratos únicos e arquivos de áudio para criar vídeos realistas de cabeças falantes para uma ampla variedade de cenários, como mensagens personalizadas, conteúdo educacional e muito mais. O uso revolucionário de tecnologias de modelagem 3D, como ExpNet e PoseVAE, é excelente para capturar as facetas sutis...
Introdução geral O VideoReTalking é um sistema inovador que permite aos usuários gerar vídeos faciais sincronizados com os lábios com base no áudio de entrada, produzindo vídeos de saída de alta qualidade e sincronizados com os lábios, mesmo com emoções diferentes. O sistema divide esse objetivo em três tarefas sucessivas: geração de vídeos faciais com expressões típicas...
Introdução geral O MuseV é um projeto público no GitHub que tem como objetivo permitir a geração de vídeos de avatar com duração ilimitada e alta fidelidade. Ele se baseia na tecnologia de difusão e oferece Image2Video, Text2Image2Video, Video2Video e muitos outros recursos. Fornece estrutura de modelo, casos de uso, início rápido...
Introdução abrangente O Unstructured-IO fornece um conjunto de componentes de código aberto para processamento e pré-processamento de imagens e documentos de texto, como PDF, HTML, documentos do Word etc. O Unstructured-IO fornece um conjunto de componentes de código aberto para processamento e pré-processamento de imagens e documentos de texto, como PDF, HTML, documentos do Word etc. Seu principal objetivo é simplificar e otimizar os fluxos de trabalho de processamento de dados, especialmente para aplicativos de modelo de linguagem grande (LLM), para fornecer suporte. Seu principal objetivo é simplificar e otimizar os fluxos de trabalho de processamento de dados, especialmente para aplicativos de modelo de linguagem grande (LLM) para fornecer suporte.
Introdução geral magic-html é uma biblioteca Python projetada para simplificar o processo de extração do conteúdo da região do corpo do HTML. Seja lidando com estruturas complexas de HTML ou com páginas da Web simples, essa biblioteca tem como objetivo fornecer uma interface conveniente e eficiente para os usuários. Ela oferece suporte à extração multimodal, extração de vários layouts...
WebPilot Introdução geral O Webpilot é um "assistente da Web" gratuito e de código aberto que permite que você se comunique livremente com qualquer página da Web ou execute tarefas automatizadas. Em vez de alternar entre páginas ou copiar e colar, basta selecionar o texto ou digitar comandos, e o Webpilot fornecerá informações em tempo real e tarefas inteligentes...
Introdução abrangente O DB-GPT é uma estrutura de desenvolvimento de aplicativos de dados nativos de IA de código aberto criada usando AWEL (Agentic Workflow Expression Language) e tecnologias de corpo inteligente. O projeto tem como objetivo criar uma infraestrutura no campo de modelos grandes por meio do desenvolvimento de vários recursos técnicos, incluindo um sistema de gerenciamento de vários modelos (SMMF),...
DreamTalk Introdução abrangente O DreamTalk é uma estrutura de geração de talking head de expressão orientada por modelo de difusão, desenvolvida em conjunto pela Universidade de Tsinghua, pelo Grupo Alibaba e pela Universidade de Ciência e Tecnologia de Huazhong. Ele consiste principalmente em três partes: uma rede de redução de ruído, um especialista em lábios com reconhecimento de estilo e um preditor de estilo, e é capaz de gerar uma variedade de entradas de áudio com base em...
Introdução abrangente O InstantID é uma tecnologia avançada voltada para a geração de imagens com estilos ou poses personalizados em segundos, garantindo um alto nível de fidelidade com o uso de uma única imagem de identificação de referência. A tecnologia usa uma solução baseada em modelo de difusão, integrando imagens faciais, imagens de...
Não consegue encontrar ferramentas de IA? Tente aqui!
Basta digitar a palavra-chave Acessibilidade Bing SearchA seção Ferramentas de IA deste site é uma maneira rápida e fácil de encontrar todas as ferramentas de IA deste site.