近日,中央网信办启动了“清朗·整治AI技术滥用”专项行动,针对当前人工智能发展中出现的若干问题划定了清晰的治理红线。此举旨在引导AI技术健康发展,防范潜在风险。该专项行动聚焦13个重点方向,分为两个阶段实施,对AI产品、服务、内容及行为规范提出了细致要求。
第一阶段:源头治理与基础建设
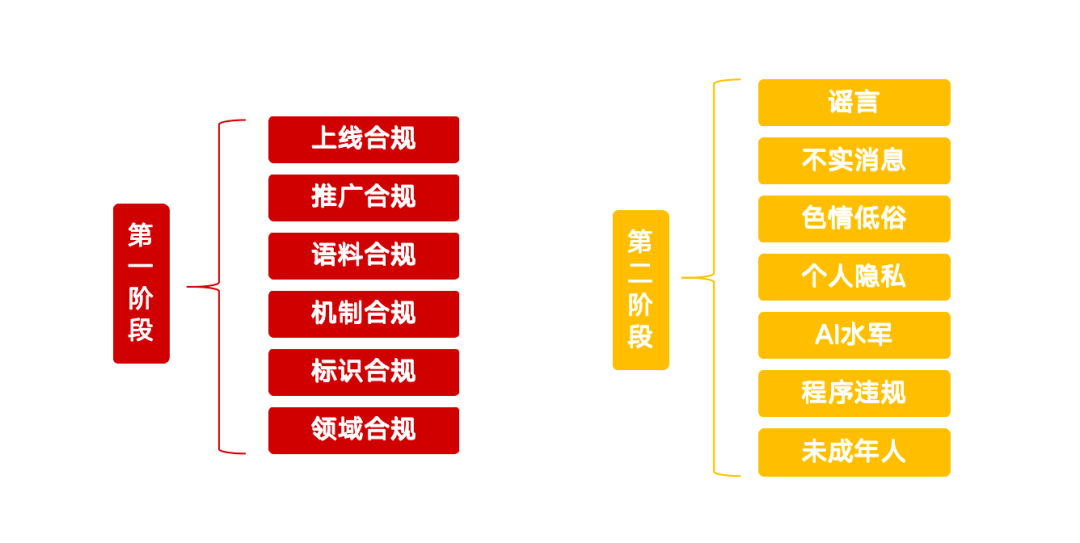
行动的第一阶段着重于AI技术的源头治理,目标是清理违规AI应用,强化内容标识管理,并提升平台的检测鉴伪能力。
违规AI产品需完成上线合规
监管部门指出,利用生成式人工智能技术向公众提供服务的应用,必须履行大模型备案或登记程序。这一要求依据《生成式人工智能服务管理暂行办法》(下称《暂行办法》)第十七条,该办法明确AI产品在正式上线前需通过安全评估。备案周期通常预计为3至6个月。此外,提供如“一键脱衣”等违法违背伦理的功能,或未经授权克隆、编辑他人生物特征(如声音、人脸)均属违规。
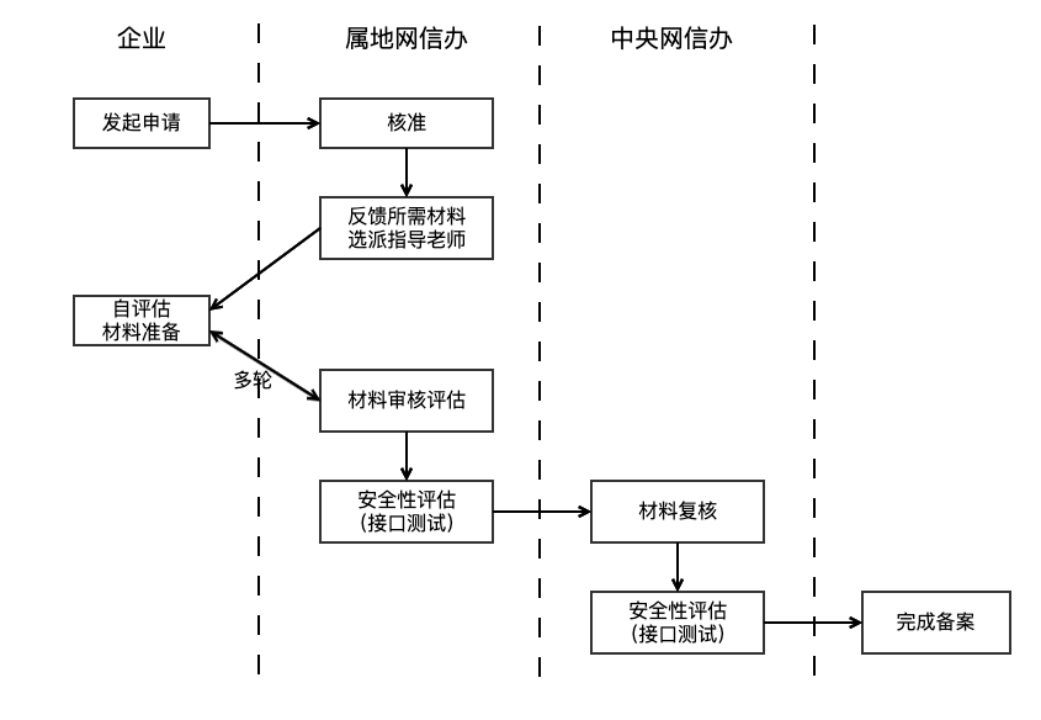
识别并监管未备案的AI服务成为一项挑战。监管机构可能运用网络爬虫等技术手段,监测各类平台,通过识别服务是否调用大模型 API 接口(如对话生成、图像合成)及其技术特征来判断。对于功能设计的合规性,除了企业内部法务评估和应用商店审核外,对非正规渠道服务的监管,目前更多依赖用户投诉举报。服务提供者应自查AI产品是否完成双备案(大模型备案与算法备案),并确保功能设计符合规范。
推广合规:严查违规AI产品教程与商品
专项行动也关注AI产品的推广环节。传授利用违规AI产品制作换脸视频、换声音频的教程,售卖“语音合成器”、“换脸工具”等违规商品,以及营销炒作不合规AI产品均在整治之列。推广者在选择推广AI产品前,有责任核查其合规性。平台方需加强内容审核,不仅要确保内容本身合法,还需具备识别和审核内容中所推广AI产品合规性的能力,例如通过语义模型初步筛选,再辅以人工介入。
语料合规:训练数据来源与管理受重视
训练数据的合规性是AI模型安全的基础。《暂行办法》第七条强调服务提供者应使用合法来源的数据和基础模型。《生成式人工智能服务安全基本要求》(下称《基本要求》)则进一步细化,规定若语料中违法不良信息超过5%,则不应采集该来源。同时,对数据来源多样性、开源协议遵循、自采数据记录及商业数据采购的法律程序均有明确规定。
由于涉及数据隐私和技术机密,训练语料的监管颇具难度,通常采取问询和材料证明方式。企业在管理海量、来源复杂、质量不一的训练数据时也面临巨大挑战。《基本要求》建议企业结合关键词过滤、分类模型筛选和人工抽检等多种手段,清理语料中的违法不良信息。
机制合规:强化安全管理措施
企业需建立与业务规模相适应的内容审核、意图识别等安全机制,并建立有效的违规账号管理流程和定期安全自评估制度。对于通过 API 接口接入的AI自动回复等服务,社交平台需做到心中有数,严格把关。《基本要求》第七章要求服务提供者监测用户输入,对多次输入违法信息的用户采取限制服务等措施。此外,企业应配备与服务规模匹配的监看人员,负责跟踪政策、分析投诉,以提升内容质量与安全。健全的风险控制机制是AI产品上线的前提。
标识合规:落实AI生成内容标识要求
为提升透明度,《人工智能生成合成内容标识办法》(下称《标识办法》)规定,服务提供者需对深度合成内容添加显式或隐式标识,并在用户下载、复制时确保文件中包含显式标识,同时在元数据中添加隐式标识。该办法配套国家标准《网络安全技术 人工智能生成合成内容标识方法》,并将于2025年9月1日起施行。企业需依据此进行自查,并部署技术手段检测平台内AI生成内容,对疑似内容进行提示。监管部门也可能加强用户教育,提升公众对AI生成内容的辨识力。
领域合规:关注重点行业安全风险
已备案的AI产品若提供医疗、金融、未成年人等重点领域的问答服务,必须针对性设置行业安全审核与控制措施。防止出现“AI开处方”、诱导投资或利用“AI幻觉”误导用户的现象。这些特定领域的合规治理复杂且细分,需要领域专家知识和专门的合规语料库支持。行业监管机构和头部企业在制定标准、保障安全措施落地方面将扮演关键角色。通用解决措施包括幻觉检测、关键操作人工审批等,以防范AI失控风险。
第二阶段:严打利用AI从事违法违规活动
专项行动的第二阶段将集中处理利用AI技术制作传播谣言、不实信息、色情低俗内容,以及假冒他人、从事网络水军活动等问题。
打击利用AI制作发布谣言
整治范围包括无中生有捏造涉时政、民生等谣言,恶意解读政策,借突发事件编造细节,冒充官方发布信息,以及利用AI认知偏差进行恶意引导。中国互联网联合辟谣平台早已运作,但在AI时代,谣言生产成本降低、逼真度提升,构成了新的治理难题。监管主要依赖舆情监控和用户举报,对重点领域AI谣言或将加大处罚力度。服务提供商需提升对AI生成谣言的检测能力,如利用AI工具校验内容准确性、监测异常账户行为、人工抽查热点内容等。
清理利用AI制作发布不实信息
此类行为包括将无关图文视频拼凑剪辑生成虚实混杂信息,模糊篡改事实要素翻炒旧闻,发布涉专业领域的夸大或伪科学内容,以及借助AI算命占卜等传播迷信。相较谣言,不实信息主观恶意可能较弱,但其隐蔽性和潜在影响不容忽视。治理主要依靠内容平台加强生态建设,通过技术手段识别低质内容,并对相关内容和创作者采取限制传播或处罚措施。
整治利用AI制作发布色情低俗内容
利用AI“一键脱衣”、AI绘图等生成色情或不雅图片视频,制作软色情、二次元擦边形象,以及血腥暴力、恐怖怪诞画面和“小黄文”等均在打击之列。AI技术在提高内容生产效率的同时,也可能被滥用于制造此类不良内容。传统审核方式如关键词库、语义模型、图像分类(“鉴黄模型”)等,对识别用户生成内容(UGC)已相对成熟。但AI生成内容的特征分布可能与UGC不同,服务提供者需注意更新模型训练数据,以保持识别准确率。
查处利用AI假冒他人实施侵权违法行为
通过AI换脸、声音克隆等深度伪造技术假冒公众人物进行欺骗或牟利,恶搞、抹黑公众人物或历史人物,利用AI冒充亲友诈骗,以及不当使用AI“复活逝者”、滥用逝者信息等行为,均属重点整治对象。此类风险源于个人隐私数据的泄露和滥用。提升公众隐私防护意识,并从长远考虑建立数据溯源机制,确保数据全链路合规至关重要。
打击利用AI从事网络水军活动
“AI水军”是网络水军的新变种。利用AI技术“养号”批量注册运营社交账号,利用AI内容农场或AI洗稿批量生成低质同质化内容刷流量,以及使用AI群控软件、社交机器人刷量控评等行为将被严厉打击。治理需从内容和账号两个维度入手,检测平台内低质及AIGC内容,监测发布AIGC内容的账号行为特征,并自动化快速干预,以提高水军作恶成本。
规范AI产品服务和应用程序行为
制作和传播仿冒、套壳AI网站和应用,AI应用提供违规功能(如创作工具提供“热搜热榜扩写”),AI社交陪聊软件提供低俗软色情对话服务,以及售卖、推广引流违规AI应用、服务或课程等,均在整治范围。这再次强调了AI产品上线和传播的合规性,并补充了对“套壳”及违规功能的界定。服务提供者应坚守技术服务于人的初衷。
保护未成年人权益免受AI侵害
AI应用诱导未成年人沉迷,或在未成年人模式下仍存在影响其身心健康的内容,是本次专项行动的又一重点。AI模型基于概率统计,其生成内容存在不可预测性,可能输出错误价值观,对未成年人成长构成潜在风险。因此,在未成年人教育场景中应用AI需格外谨慎,严格控制使用场景;在未成年人高频接触的其他产品中,应强化未成年人模式,限制AI应用权限。