Find My Kids:通过人脸识别和WhatsApp通知的儿童安全监控工具
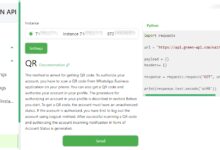
综合介绍 Find My Kids 是一个开源项目,托管在 GitHub 上,由开发者 Tomer Klein 创建。它结合了 DeepFace 人脸识别技术和 WhatsApp Green API,旨在帮助家长通过 WhatsApp 群组监控孩子的安全。用户可以在群组...

综合介绍 Find My Kids 是一个开源项目,托管在 GitHub 上,由开发者 Tomer Klein 创建。它结合了 DeepFace 人脸识别技术和 WhatsApp Green API,旨在帮助家长通过 WhatsApp 群组监控孩子的安全。用户可以在群组...

综合介绍 YOLOE 是清华大学软件学院多媒体智能组(THU-MIG)开发的一个开源项目,全称“You Only Look Once Eye”。它基于 PyTorch 框架,属于 YOLO 系列的扩展,能实时检测和分割任何物体。项目托管在 GitHub 上,...

开启 Builder 智能编程模式,无限量使用 DeepSeek-R1 和 DeepSeek-V3 ,对比海外版体验更加流畅。只需输入中文指令,不懂编程的小白也可以零门槛编写自己的应用。
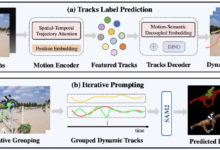
综合介绍 SegAnyMo 是一个开源项目,由加州大学伯克利分校和北京大学的研究团队开发,包括 Nan Huang 等成员。这个工具专注于视频处理,能自动识别和分割视频中任意运动的物体,比如人、动物或车辆。它结合了 TAP...

综合介绍 RF-DETR 是 Roboflow 团队开发的一个开源对象检测模型。它基于 Transformer 架构,核心特点是实时高效。模型在微软 COCO 数据集上首次实现超过 60 AP 的实时检测,同时在 RF100-VL 基准测试中表现突出,...

综合介绍 HumanOmni 是由 HumanMLLM 团队开发的一个开源多模态大模型,托管在 GitHub 上。它专注于分析人类视频,能同时处理画面和声音,帮助理解情感、动作和对话内容。项目用了 240 万个以人为中心的视频片段和...

综合介绍 Vision Agent 是由 LandingAI(吴恩达团队) 开发的一个开源项目,托管在 GitHub 上,旨在帮助用户快速生成解决计算机视觉任务的代码。它利用先进的代理框架和多模态模型,通过简单的提示即可生成高效的...

综合介绍 Make Sense 是一个免费的在线图像标注工具,旨在帮助用户快速为计算机视觉项目准备数据集。它无需复杂安装,只需打开浏览器访问即可使用,支持多种操作系统,非常适合小型深度学习项目。用户可以通过它...

综合介绍 YOLOv12 是由 GitHub 用户 sunsmarterjie 开发的一个开源项目,专注于实时目标检测技术。该项目基于 YOLO(You Only Look Once)系列框架,引入注意力机制优化传统卷积神经网络(CNN)的性能,不仅在检...

综合介绍 VLM-R1 是由 Om AI Lab 开发的一个开源视觉语言模型项目,托管在 GitHub 上。该项目基于 DeepSeek 的 R1 方法,结合 Qwen2.5-VL 模型,通过强化学习(R1)和监督微调(SFT)技术,显著提升了模型在视觉...
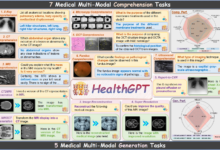
综合介绍 HealthGPT 是一个先进的医疗大视觉语言模型,旨在通过异构知识适应实现统一的医学视觉理解和生成功能。该项目的目标是将医学视觉理解和生成能力集成到一个统一的自回归框架中,显著提升了医疗图像处理的...

综合介绍 MedRAX是一个专为胸部X光片(CXR)分析设计的先进AI智能体。它集成了最先进的CXR分析工具和多模态大语言模型,能够动态处理复杂的医学查询,而无需额外训练。MedRAX通过其模块化设计和强大的技术基础,...

综合介绍 Agentic Object Detection 是由 Landing AI 推出的先进目标检测工具。该工具通过文本提示进行检测,无需进行数据标注和模型训练,极大地简化了传统目标检测的流程。用户只需上传图像并输入检测提示,AI ...

综合介绍 CogVLM2 是由清华大学数据挖掘研究组(THUDM)开发的开源多模态模型,基于 Llama3-8B 架构,旨在提供与 GPT-4V 相当甚至更优的性能。该模型支持图像理解、多轮对话以及视频理解,能够处理长达 8K 的内容...

综合介绍 Gaze-LLE是一款基于大规模学习编码器的注视目标预测工具。该项目由Fiona Ryan、Ajay Bati、Sangmin Lee、Daniel Bolya、Judy Hoffman和James M. Rehg开发,旨在通过预训练的视觉基础模型(如DINOv2)实...

综合介绍 视频分析工具(Video Analyzer)是一个综合性的视频分析工具,结合了计算机视觉、音频转录和自然语言处理技术,能够生成详细的视频内容描述。该工具通过提取视频中的关键帧,转录音频内容,并生成自然语...

综合介绍 Twelve Labs是一家专注于视频理解的多模态AI公司,致力于通过先进的AI技术帮助用户理解和处理大量视频内容。其核心技术包括视频搜索、生成和嵌入,能够从视频中提取关键特征,如动作、对象、屏幕文本、...