微调开源大语言模型
这种方法是在客户的语料库上微调像 Llama2 这样的开源大语言模型。微调后的模型能够吸收并理解客户的特定领域知识,从而无需额外上下文就能回答相关问题。然而,值得注意的是,许多客户的语料库规模有限,且常常包含语法错误。这在微调大语言模型时可能会带来挑战。不过,在下文讨论的检索增强生成技术中使用微调后的大语言模型时,已经观察到了令人鼓舞的结果。
检索增强生成
解决这个问题的第二种方法是检索增强生成 (RAG)。这种方法首先将数据分块,然后存储在向量数据库中。在回答问题时,系统会根据查询检索出最相关的数据块,并将其传递给大语言模型来生成答案。目前,一些结合了大语言模型、向量存储和编排框架的开源技术方案在互联网上颇受欢迎。下文将展示一个使用 RAG 技术的解决方案示意图。

然而,使用上述方法构建解决方案时会面临一些挑战。该解决方案的性能取决于多个因素,如文本分块大小、分块间的重叠程度、嵌入技术等,而用户需要自行确定每个因素的最佳设置。以下是可能影响性能的几个关键因素:
文档分块大小
如前所述,大语言模型的上下文长度是有限的,因此需要将文档分成小块。然而,分块的大小对解决方案的性能至关重要。过小的分块无法回答需要分析跨多个段落信息的问题,而过大的分块会迅速占用上下文长度,导致能处理的分块数量减少。此外,分块大小与嵌入技术共同决定了检索到的分块与问题的相关性。
相邻分块之间的重叠
分块时需要适当的重叠,以确保信息不会被生硬地切断。理想情况下,应确保回答问题所需的所有上下文至少完整地存在于一个分块中。然而,过高的重叠度虽然可以解决这个问题,但也会带来新的挑战:多个重叠的分块包含相似信息,导致搜索结果中充满重复内容。
嵌入技术
嵌入技术是将文本分块转换为向量的算法,这些向量随后存储在文档检索器中。用于嵌入分块和问题的技术决定了检索到的分块与问题的相关性,进而影响提供给大语言模型的内容质量。
文档检索器
文档检索器(也称为向量存储)是用于存储嵌入向量并快速检索的数据库。检索器中用于匹配最近邻的算法(如点积、余弦相似度)决定了检索到的分块的相关性。此外,文档检索器应能够水平扩展以支持大型知识库。
大语言模型
选择合适的大语言模型是解决方案的关键组成部分。最佳模型的选择取决于多个因素,包括数据集特点和上述其他因素。为优化解决方案,建议尝试不同的大语言模型,并确定哪一个能提供最佳结果。虽然一些组织乐于采用这种方法,但其他组织可能受限于不能使用 GPT4、Palm 或 Claude 等闭源大语言模型。Abacus.AI 提供了多种大语言模型选项,包括 GPT3.5、GPT4、Palm、Azure OpenAI、Claude、Llama2,以及 Abacus.AI 的专有模型。此外,Abacus.AI 能够在用户数据上微调大语言模型,并将其用于检索增强生成技术,从而兼顾两方面的优势。
分块数量
有些问题的回答需要文档不同部分甚至跨文档的信息。例如,回答"列举一些包含野生动物的电影"这样的问题需要来自不同电影的片段或分块。有时,最相关的分块可能不会出现在向量搜索的顶部。在这些情况下,向大语言模型提供多个数据分块进行评估和生成响应非常重要。
调整上述每个参数都需要用户付出大量努力,并涉及繁琐的手动评估过程。
Abacus.AI 的解决方案
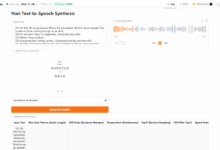
为解决这个问题,Abacus.AI 采用了一种创新方法,为用户提供 AutoML 功能。这种方法可以自动迭代各种参数组合,包括微调大语言模型,从而找到最适合特定用例的最佳组合。除了用户提供的文档外,还需要一个评估数据集,其中包含一系列问题和相应的人工编写的标准答案。Abacus.AI 使用这个评估集来比较不同参数组合生成的回答,从而确定最佳配置。

Abacus.AI 生成了以下几项评估指标,用户可以选择自己偏好的指标来判断哪种组合表现最好。
BLEU 分数
BLEU(双语评估替代)分数是一种常用的自动评估指标,主要用于评估机器翻译的质量。它的目的在于提供一个与人类评分高度相关的翻译质量的定量测量。
BLEU 分数通过将候选翻译(机器输出的翻译)与一个或多个参考翻译(人类生成的翻译)进行对比,计算候选翻译与参考翻译之间的 n-gram 重叠程度,从而得出一个分数。具体来说,它评估候选翻译中 n-gram(即 n 个单词的序列)与参考翻译中的精确匹配程度。
METEOR 分数
METEOR(显式排序翻译评估指标)分数是另一种自动评估指标,常用于评估机器翻译的质量。它的设计旨在弥补 BLEU 等其他评估指标的一些不足,特别是通过引入显式的词序匹配并考虑同义词和改写的方式。
BERT 分数
BERT 分数是一种旨在评估文本生成质量的自动评估指标。该分数通过计算候选句子和参考句子中各个 Token 之间的相似度来得出结果。与精确匹配不同,这一指标利用上下文嵌入来判断 Token 的相似性。
ROUGE 分数
ROUGE(针对摘要评估的回召导向替代者)分数是一组常用于自然语言处理和文本摘要的自动评估指标。最初,这些指标是为了评估文本摘要系统的质量而设计的,但现在它们也广泛应用于机器翻译和文本生成等其他领域。
ROUGE 分数通过将生成的文本(例如摘要或翻译)与一个或多个参考文本(通常是人类生成的摘要或翻译)进行比较,来衡量生成文本的质量。它主要测量候选文本与参考文本之间的 n-gram(即 n 个单词的序列)和单词序列的重叠程度。

上述每个分数的范围是 0 到 1,分数越高,说明模型的表现越好。借助 Abacus.AI,您可以尝试多种模型和指标,迅速找到在您的数据和具体应用中效果最佳的方案。